Six ways to Sunday: approaches to computational reproducibility in non-model system sequence analysis. презентация
Содержание
- 2. Hello! Assistant Professor; Microbiology; Computer Science; etc. More information at: ged.msu.edu/
- 3. The challenges of non-model sequencing Missing or low quality genome reference.
- 4. Shotgun sequencing & assembly
- 5. Shotgun sequencing analysis goals: Assembly (what is the text?) Produces new
- 6. Assembly It was the best of times, it was the wor
- 8. Introducing k-mers
- 9. K-mers give you an implicit alignment CCGATTGCACTGGACCGATGCACGGTACCGTATAGCC CATGGACCGATTGCACTGGACCGATGCACGGTACCG
- 10. K-mers give you an implicit alignment CCGATTGCACTGGACCGATGCACGGTACCGTATAGCC CATGGACCGATTGCACTGGACCGATGCACGGTACCG CATGGACCGATTGCACTGGACCGATGCACGGACCG
- 11. De Bruijn graphs – assemble on overlaps
- 12. The problem with k-mers CCGATTGCACTGGACCGATGCACGGTACCGTATAGCC CATGGACCGATTGCACTCGACCGATGCACGGTACCG
- 13. Assembly graphs scale with data size, not information.
- 14. Practical memory measurements (soil)
- 15. Data set size and cost $1000 gets you ~100m “reads”, or
- 16. Efficient data structures & algorithms
- 17. Shotgun sequencing is massively redundant; can we eliminate redundancy while retaining
- 18. Sparse collections of k-mers can be stored efficiently in Bloom filters
- 19. Data structures & algorithms papers “These are not the k-mers you
- 20. Data analysis papers “Tackling soil diversity with the assembly of large,
- 21. Lab approach – not intentional, but working out.
- 22. This leads to good things.
- 24. Testing & version control – the not so secret sauce High
- 25. On the “novel research” side: Novel data structures and algorithms; Permit
- 26. Running entirely w/in cloud
- 27. On the “novel research” side: Novel data structures and algorithms; Permit
- 28. Reproducibility! Scientific progress relies on reproducibility of analysis. (Aristotle, Nature, 322
- 29. Disclaimer Not a researcher of reproducibility! Merely a practitioner. Please
- 30. My usual intro: We practice open science! Everything discussed here: Code:
- 31. My usual intro: We practice open science! Everything discussed here: Code:
- 32. My lab & the diginorm paper. All our code was already
- 33. IPython Notebook: data + code =>
- 34. My lab & the diginorm paper. All our code was already
- 35. To reproduce our paper: git clone <khmer> && python setup.py install
- 36. Now standard in lab --
- 37. Research process
- 38. Literate graphing & interactive exploration
- 39. The process We start with pipeline reproducibility Baked into lab culture;
- 40. Growing & refining the process Now moving to Ubuntu Long-Term Support
- 41. 1. Use standard OS; provide install instructions Providing install, execute for
- 42. 2. Automate Literate graphing now easy with knitr and IPython Notebook.
- 43. Myths of reproducible research (Opinions from personal experience.)
- 44. Myth 1: Partial reproducibility is hard. “Here’s my script.” =>
- 45. Myth 2: Incomplete reproducibility is useless Paraphrase: “We can’t possibly reproduce
- 46. Myth 3: We need new platforms Techies always want to build
- 47. Myth 4. Virtual Machine reproducibility is an end solution. Good start!
- 48. Myth 5: We can use GUIs for reproducible research (OK, this
- 49. Our current efforts? Semantic versioning of our own code: stable command-line
- 50. khmer-protocols
- 51. khmer-protocols: Provide standard “cheap” assembly protocols for the cloud. Entirely copy/paste;
- 52. Literate testing Our shell-command tutorials for bioinformatics can now be executed
- 53. Doing things right => #awesomesauce
- 54. Concluding thoughts We are not doing anything particularly neat on the
- 55. What bits should people adopt? Version control! Literate graphing! Automated “build”
- 56. More concluding thoughts Nobody would care that we were doing things
- 57. Biology & sequence analysis is in a perfect place for reproducibility
- 58. Thanks! Talk is on slideshare: slideshare.net/c.titus.brown E-mail or tweet me: ctb@msu.edu
- 59. Скачать презентацию





Produces new")








")



























")















Слайды и текст этой презентации
Слайд 1
Описание слайда:
Six ways to Sunday: approaches to computational reproducibility in non-model system sequence analysis.
C. Titus Brown
ctb@msu.edu
May 21, 2014
Слайд 2
Описание слайда:
Hello!
Assistant Professor; Microbiology; Computer Science; etc.
More information at:
ged.msu.edu/
github.com/ged-lab/
ivory.idyll.org/blog/
@ctitusbrown
Слайд 3
Описание слайда:
The challenges of non-model sequencing
Missing or low quality genome reference.
Evolutionarily distant.
Most extant computational tools focus on model organisms –
Assume low polymorphism (internal variation)
Assume reference genome
Assume somewhat reliable functional annotation
More significant compute infrastructure
…and cannot easily or directly be used on critters of interest.
Слайд 4
Описание слайда:
Shotgun sequencing & assembly
Слайд 5
Описание слайда:
Shotgun sequencing analysis goals:
Assembly (what is the text?)
Produces new genomes & transcriptomes.
Gene discovery for enzymes, drug targets, etc.
Counting (how many copies of each book?)
Measure gene expression levels, protein-DNA interactions
Variant calling (how does each edition vary?)
Discover genetic variation: genotyping, linkage studies…
Allele-specific expression analysis.
Слайд 6
Описание слайда:
Assembly
It was the best of times, it was the wor
, it was the worst of times, it was the
isdom, it was the age of foolishness
mes, it was the age of wisdom, it was th
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness
…but for lots and lots of fragments!
Слайд 7
Описание слайда:
Слайд 8
Описание слайда:
Introducing k-mers
Слайд 9
Описание слайда:
K-mers give you an implicit alignment
CCGATTGCACTGGACCGATGCACGGTACCGTATAGCC
CATGGACCGATTGCACTGGACCGATGCACGGTACCG
Слайд 10
Описание слайда:
K-mers give you an implicit alignment
CCGATTGCACTGGACCGATGCACGGTACCGTATAGCC
CATGGACCGATTGCACTGGACCGATGCACGGTACCG
CATGGACCGATTGCACTGGACCGATGCACGGACCG
(with no accounting for mismatches or indels)
Слайд 11
Описание слайда:
De Bruijn graphs – assemble on overlaps
Слайд 12
Описание слайда:
The problem with k-mers
CCGATTGCACTGGACCGATGCACGGTACCGTATAGCC
CATGGACCGATTGCACTCGACCGATGCACGGTACCG
Слайд 13
Описание слайда:
Assembly graphs scale with data size, not information.
Слайд 14
Описание слайда:
Practical memory measurements (soil)
Слайд 15
Описание слайда:
Data set size and cost
$1000 gets you ~100m “reads”, or about 10-40 GB of data, in ~week.
> 1000 labs doing this regularly.
Each data set analysis is ~custom.
Analyses are data intensive and memory intensive.
Слайд 16
Описание слайда:
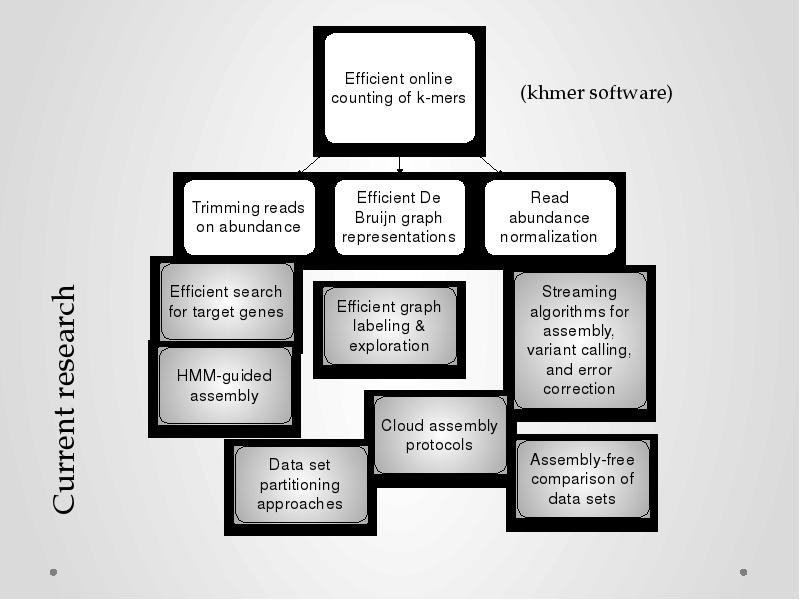
Efficient data structures & algorithms
Слайд 17
Описание слайда:
Shotgun sequencing is massively redundant; can we eliminate redundancy while retaining information?
Слайд 18
Описание слайда:
Sparse collections of k-mers can be stored efficiently in Bloom filters
Слайд 19
Описание слайда:
Data structures & algorithms papers
“These are not the k-mers you are looking for…”, Zhang et al., arXiv 1309.2975, in review.
“Scaling metagenome sequence assembly with probabilistic de Bruijn graphs”, Pell et al., PNAS 2012.
“A Reference-Free Algorithm for Computational Normalization of Shotgun Sequencing Data”, Brown et al., arXiv 1203.4802, under revision.
Слайд 20
Описание слайда:
Data analysis papers
“Tackling soil diversity with the assembly of large, complex metagenomes”, Howe et al., PNAS, 2014.
Assembling novel ascidian genomes & transcriptomes, Lowe et al., in prep.
A de novo lamprey transcriptome from large scale multi-tissue mRNAseq, Scott et al., in prep.
Слайд 21
Описание слайда:
Lab approach – not intentional, but working out.
Слайд 22
Описание слайда:
This leads to good things.
Слайд 23
Описание слайда:
Слайд 24
Описание слайда:
Testing & version control – the not so secret sauce
High test coverage - grown over time.
Stupidity driven testing – we write tests for bugs after we find them and before we fix them.
Pull requests & continuous integration – does your proposed merge break tests?
Pull requests & code review – does new code meet our minimal coding etc requirements?
Note: spellchecking!!!
Слайд 25
Описание слайда:
On the “novel research” side:
Novel data structures and algorithms;
Permit low(er) memory data analysis;
Liberate analyses from specialized hardware.
Слайд 26
Описание слайда:
Running entirely w/in cloud
Слайд 27
Описание слайда:
On the “novel research” side:
Novel data structures and algorithms;
Permit low(er) memory data analysis;
Liberate analyses from specialized hardware.
This last bit? => reproducibility.
Слайд 28
Описание слайда:
Reproducibility!
Scientific progress relies on reproducibility of analysis. (Aristotle, Nature, 322 BCE.)
Слайд 29
Описание слайда:
Disclaimer
Not a researcher of reproducibility!
Merely a practitioner.
Please take my points below as an argument and not as research conclusions.
(But I’m right.)
Слайд 30
Описание слайда:
My usual intro:
We practice open science!
Everything discussed here:
Code: github.com/ged-lab/ ; BSD license
Blog: http://ivory.idyll.org/blog (‘titus brown blog’)
Twitter: @ctitusbrown
Grants on Lab Web site: http://ged.msu.edu/research.html
Preprints available.
Everything is > 80% reproducible.
Слайд 31
Описание слайда:
My usual intro:
We practice open science!
Everything discussed here:
Code: github.com/ged-lab/ ; BSD license
Blog: http://ivory.idyll.org/blog (‘titus brown blog’)
Twitter: @ctitusbrown
Grants on Lab Web site: http://ged.msu.edu/research.html
Preprints available.
Everything is > 80% reproducible.
Слайд 32
Описание слайда:
My lab & the diginorm paper.
All our code was already on github;
Much of our data analysis was already in the cloud;
Our figures were already made in IPython Notebook
Our paper was already in LaTeX
Слайд 33
Описание слайда:
IPython Notebook: data + code =>
Слайд 34
Описание слайда:
My lab & the diginorm paper.
All our code was already on github;
Much of our data analysis was already in the cloud;
Our figures were already made in IPython Notebook
Our paper was already in LaTeX
…why not push a bit more and make it easily reproducible?
This involved writing a tutorial. And that’s it.
Слайд 35
Описание слайда:
To reproduce our paper:
git clone <khmer> && python setup.py install
git clone <pipeline>
cd pipeline
wget <data> && tar xzf <data>
make && cd ../notebook && make
cd ../ && make
Слайд 36
Описание слайда:
Now standard in lab --
Слайд 37
Описание слайда:
Research process
Слайд 38
Описание слайда:
Literate graphing & interactive exploration
Слайд 39
Описание слайда:
The process
We start with pipeline reproducibility
Baked into lab culture; default “use git; write scripts”
Community of practice!
Use standard open source approaches, so OSS developers learn it easily.
Enables easy collaboration w/in lab
Valuable learning tool!
Слайд 40
Описание слайда:
Growing & refining the process
Now moving to Ubuntu Long-Term Support + install instructions.
Everything is as automated as is convenient.
Students expected to communicate with me in IPython Notebooks.
Trying to avoid building (or even using) new tools.
Avoid maintenance burden as much as possible.
Слайд 41
Описание слайда:
1. Use standard OS; provide install instructions
Providing install, execute for Ubuntu Long-Term Support release 14.04: supported through 2017 and beyond.
Avoid pre-configured virtual machines!
Locks you into specific cloud homes.
Challenges remixability and extensibility.
Слайд 42
Описание слайда:
2. Automate
Literate graphing now easy with knitr and IPython Notebook.
Build automation with make, or whatever. To first order, it does not matter what tools you use.
Explicit is better than implicit. Make it easy to understand what you’re doing and how to extend it.
Слайд 43
Описание слайда:
Myths of reproducible research
(Opinions from personal experience.)
Слайд 44
Описание слайда:
Myth 1: Partial reproducibility is hard.
“Here’s my script.” => Methods
More generally,
Many scientists cannot replicate any part of their analysis without a lot of manual work.
Automating this is a win for reasons that have nothing to do with reproducibility… efficiency!
See: Software Carpentry.
Слайд 45
Описание слайда:
Myth 2: Incomplete reproducibility is useless
Paraphrase: “We can’t possibly reproduce the experimental data exactly, so we shouldn’t bother with anything else, either.”
(Analogous arg re software testing & code coverage.)
…I really have a hard time arguing the paraphrase honestly…
Being able to reanalyze your raw data? Interesting.
Knowing how you made your figures? Really useful.
Слайд 46
Описание слайда:
Myth 3: We need new platforms
Techies always want to build something (which is fun!) but don’t want to do science (which is hard!)
We probably do need new platforms, but stop thinking that building them does a service.
Platforms need to be use driven. Seriously.
If you write good software for scientific inquiry and make it easy to use reproducibly, that will drive virtuousity.
Слайд 47
Описание слайда:
Myth 4. Virtual Machine reproducibility is an end solution.
Good start! Better than nothing!
But:
Limits understanding & reuse.
Limits remixing: often cannot install other software!
“Chinese Room” argument: could be just a lookup table.
Слайд 48
Описание слайда:
Myth 5: We can use GUIs for reproducible research
(OK, this is partly just to make people think ;)
Almost all data analysis takes place within a larger pipeline; the GUI must consume entire pipeline in order to be reproducible.
IFF GUI wraps command line, that’s a decent compromise (e.g. Galaxy) but handicaps researchers using novel approaches.
By the time it’s in a GUI, it’s no longer research.
Слайд 49
Описание слайда:
Our current efforts?
Semantic versioning of our own code: stable command-line interface.
Writing easy-to-teach tutorials and protocols for common analysis pipelines.
Automate ‘em for testing purposes.
Encourage their use, inclusion, and adaptation by others.
Слайд 50
Описание слайда:
khmer-protocols
Слайд 51
Описание слайда:
khmer-protocols:
Provide standard “cheap” assembly protocols for the cloud.
Entirely copy/paste; ~2-6 days from raw reads to assembly, annotations, and differential expression analysis. ~$150 per data set (on Amazon rental computers)
Open, versioned, forkable, citable….
Слайд 52
Описание слайда:
Literate testing
Our shell-command tutorials for bioinformatics can now be executed in an automated fashion – commands are extracted automatically into shell scripts.
See: github.com/ged-lab/literate-resting/.
Tremendously improves peace of mind and confidence moving forward!
Слайд 53
Описание слайда:
Doing things right
=> #awesomesauce
Слайд 54
Описание слайда:
Concluding thoughts
We are not doing anything particularly neat on the computational side... No “magic sauce.”
Much of our effort is now driven by sheer utility:
Automation reduces our maintenance burden.
Extensibility makes revisions much easier!
Explicit instructions are good for training.
Some effort needed at the beginning, but once practices are established, “virtuous cycle” takes over.
Слайд 55
Описание слайда:
What bits should people adopt?
Version control!
Literate graphing!
Automated “build” from data => results!
Make available data as early in your pipeline as possible.
Слайд 56
Описание слайда:
More concluding thoughts
Nobody would care that we were doing things reproducibly if our science wasn’t decent.
Make sure students realize that faffing about on infrastructure isn’t science.
Research is about doing science. Reproducibility (like other good practices) is much easier to proselytize if you can link it to progress in science.
Слайд 57
Описание слайда:
Biology & sequence analysis is in a perfect place for reproducibility
We are lucky! A good opportunity!
Big Data: laptops are too small;
Excel doesn’t scale any more;
Few tools in use; most of them are $$ or UNIX;
Little in the way of entrenched research practice;
Слайд 58
Описание слайда:
Thanks!
Talk is on slideshare: slideshare.net/c.titus.brown
E-mail or tweet me:
ctb@msu.edu
@ctitusbrown
Скачать презентацию на тему Six ways to Sunday: approaches to computational reproducibility in non-model system sequence analysis. можно ниже: