Taming Big Data! презентация
Содержание
- 2. Discovery is an iterative process
- 3. Discovery in the big data era: Resource-intensive, expensive, slow
- 4. Three big data challenges Channel massive flows Automate management Build discovery
- 5. Three big data challenges Channel massive flows Automate management Build discovery
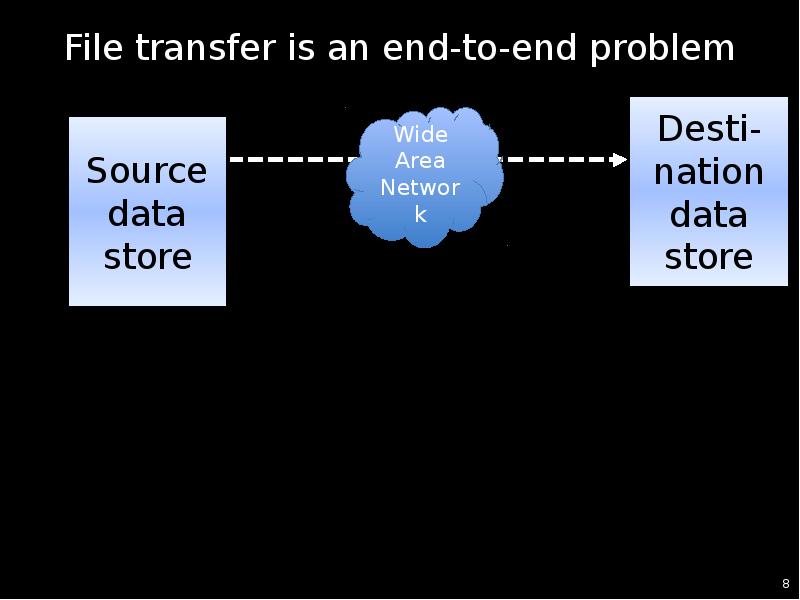
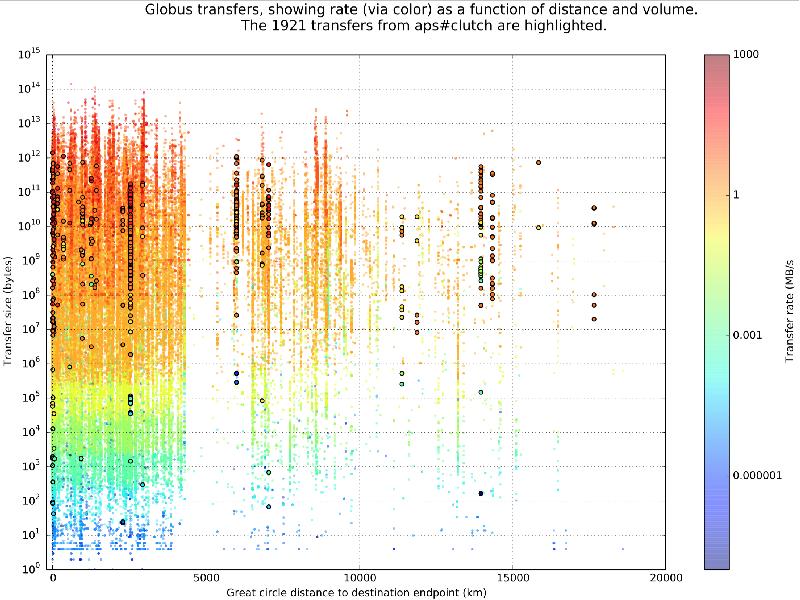
- 6. Channel massive data flows Data must move to be useful. We
- 7. Transfer is challenging at many levels Speed and reliability GridFTP protocol
- 10. GridFTP protocol and implementations: Fast, reliable, secure 3rd-party data transfer
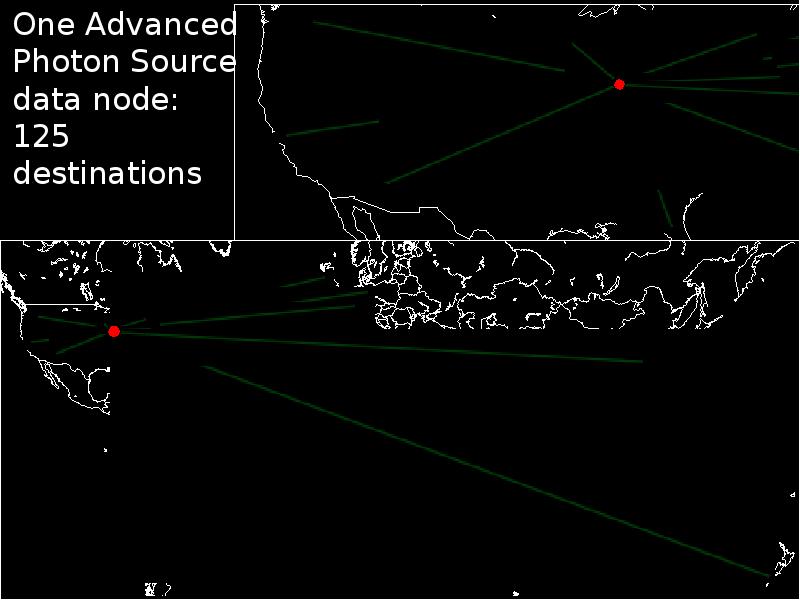
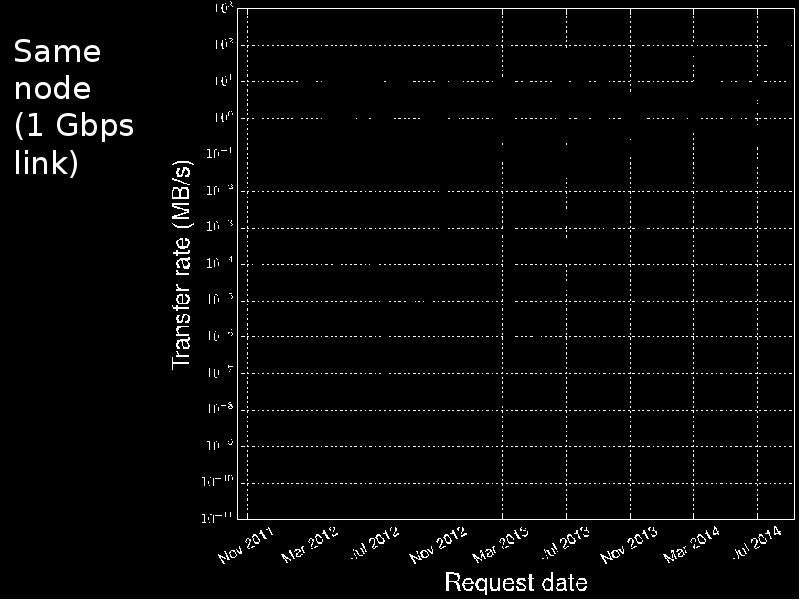
- 11. 85 Gbps sustained disk-to-disk over 100 Gbps network, Ottawa—New Orleans
- 17. Transfer scheduling and optimization Science data traffic is extremely bursty User
- 18. A load-aware, adaptive algorithm: (1) Data-driven model of throughput
- 19. A load-aware, adaptive algorithm: (2) Concurrency-constrained scheduling Define transfer priority: Schedule
- 22. Robust analytic models for science at extreme scales Gagan Agarwal1* Prasanna
- 23. How to create more accurate, useful, and portable models of distributed
- 24. Differential regression for combining data from different sources Example of use:
- 25. End-to-end profile composition
- 26. Three big data challenges Channel massive flows Automate management Build discovery
- 28. One researcher’s perspective on data management challenges
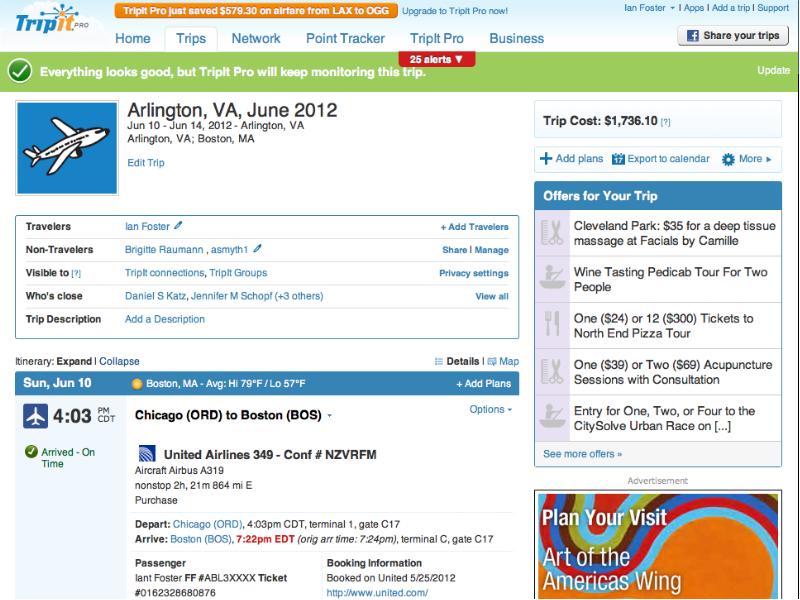
- 30. Tripit exemplifies process automation Me Book flights Book hotel
- 31. How the “business cloud” works
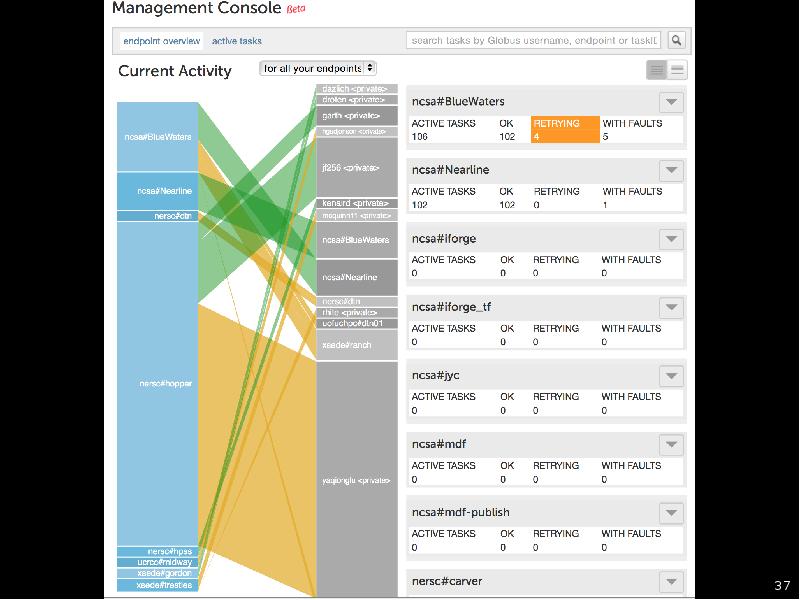
- 32. Process automation for science
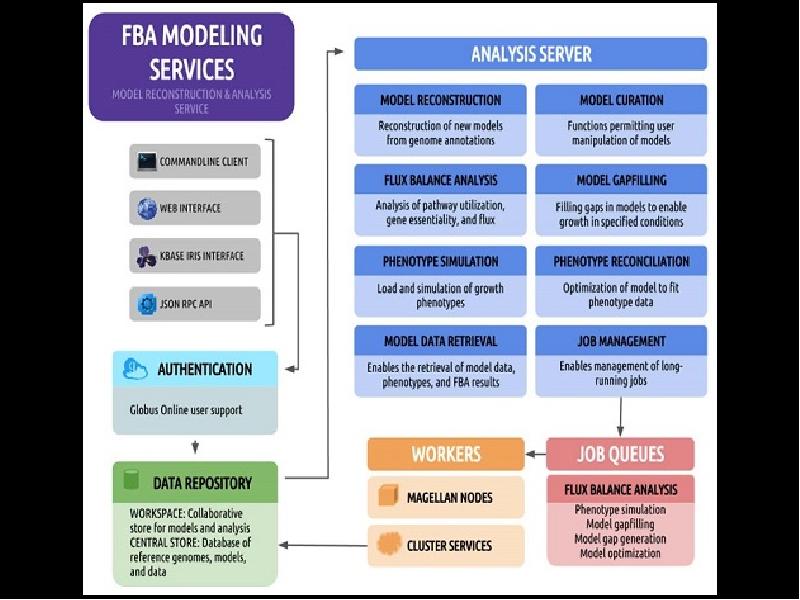
- 33. Globus research data management services
- 34. Reliable, secure, high-performance file transfer and synchronization “Fire-and-forget” transfers Automatic fault
- 35. Simple, secure sharing off existing storage systems
- 36. Extreme ease of use InCommon, Oauth, OpenID, X.509, … Credential management
- 39. High-speed transfers to/from AWS cloud, via Globus transfer service UChicago
- 40. Globus transfer & sharing; identity & group management, data discovery &
- 41. Globus under the covers
- 42. Globus under the covers
- 44. Globus Platform-as-a-Service
- 45. The Globus Galaxies platform: Science as a service
- 46. Three big data challenges Channel massive flows Automate management Build discovery
- 47. Discovery engines: Integrate simulation, experiment, and informatics
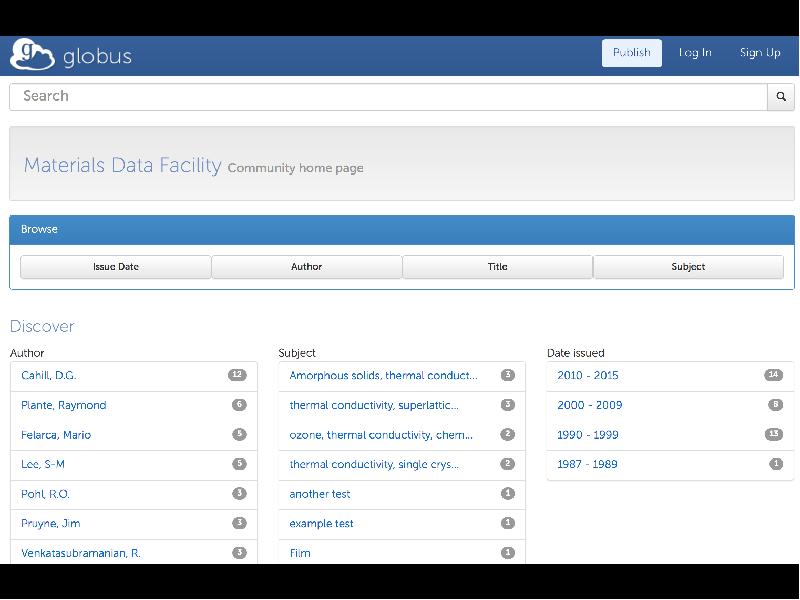
- 48. A discovery engine for metagenomics
- 50. DOE Systems Biology Knowledge Base (KBase)
- 52. A discovery engine for the study of disordered structures
- 53. Immediate assessment of alignment quality in near-field high-energy diffraction microscopy
- 54. New data, computational capabilities, and methods create opportunities and challenges
- 55. Big Data to Knowledge: bd2k.org
- 56. Three big data challenges Channel massive flows New protocols and management
- 57. My work is supported by:
- 58. Thank you! foster@anl.gov ianfoster.org
- 59. Скачать презентацию












 Data-driven model of throughput")
 Concurrency-constrained scheduling
Define transfer priority:
Schedule")

























")







Слайды и текст этой презентации
Слайд 1
Описание слайда:
Ian Foster
Argonne National Laboratory and University of Chicago
foster@anl.gov
ianfoster.org
Слайд 2
Описание слайда:
Discovery is an iterative process
Слайд 3
Описание слайда:
Discovery in the big data era:
Resource-intensive, expensive, slow
Слайд 4
Описание слайда:
Three big data challenges
Channel massive flows
Automate management
Build discovery engines
Слайд 5
Описание слайда:
Three big data challenges
Channel massive flows
Automate management
Build discovery engines
Слайд 6
Описание слайда:
Channel massive data flows
Data must move to be useful. We may optimize, but we can never entirely eliminate distance.
Sources: experimental facilities,
sensors, computations
Sinks: analysis computers,
display systems
Stores: impedance
matchers & time shifters
Pipes: IO systems and
networks connect other elements
Слайд 7
Описание слайда:
Transfer is challenging at many levels
Speed and reliability
GridFTP protocol
Globus implementation
Scheduling and modeling
SEAL and STEAL algorithms
RAMSES project
Слайд 8
Описание слайда:
Слайд 9
Описание слайда:
Слайд 10
Описание слайда:
GridFTP protocol and implementations:
Fast, reliable, secure 3rd-party data transfer
Слайд 11
Описание слайда:
85 Gbps sustained disk-to-disk over 100 Gbps network, Ottawa—New Orleans
Слайд 12
Описание слайда:
Слайд 13
Описание слайда:
Слайд 14
Описание слайда:
Слайд 15
Описание слайда:
Слайд 16
Описание слайда:
Слайд 17
Описание слайда:
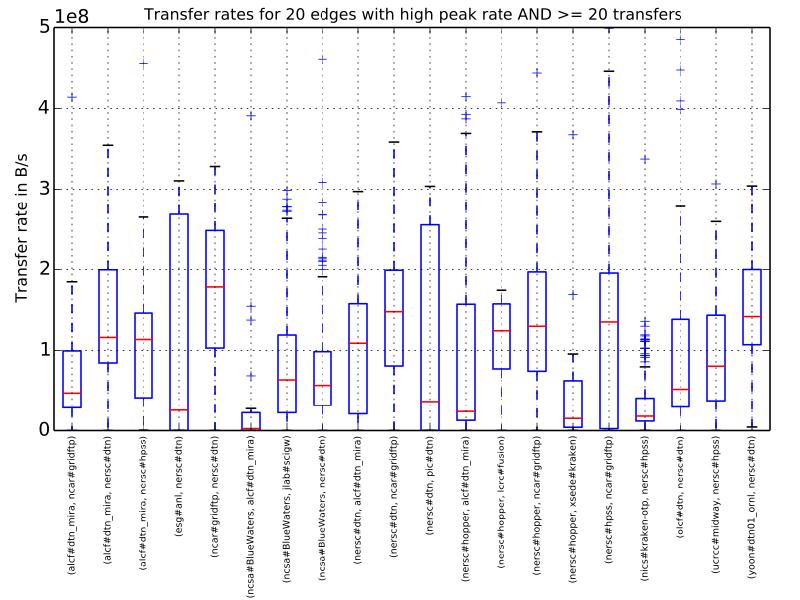
Transfer scheduling and optimization
Science data traffic is
extremely bursty
User experience can be
improved by scheduling to minimize slowdown
Traffic can be categorized: interactive or batch
Increased concurrency
tends to increase aggregate
throughput, to a point
Слайд 18
Описание слайда:
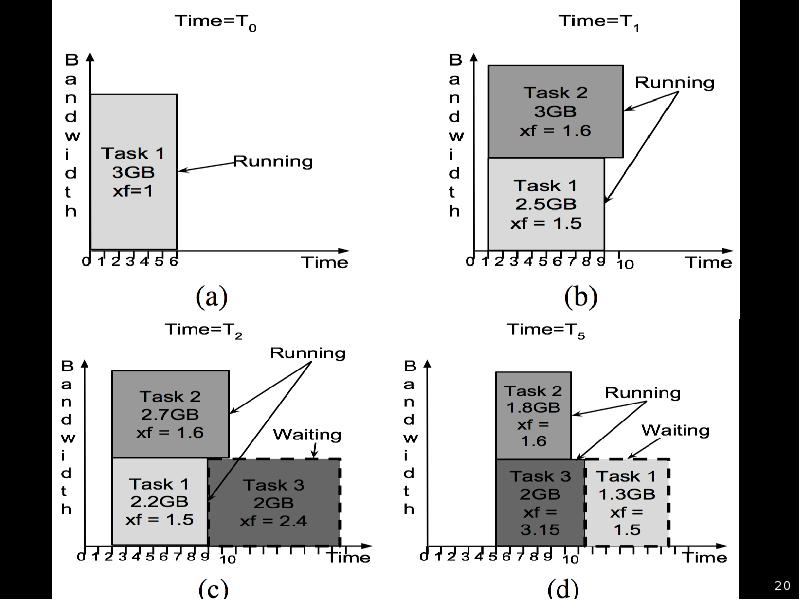
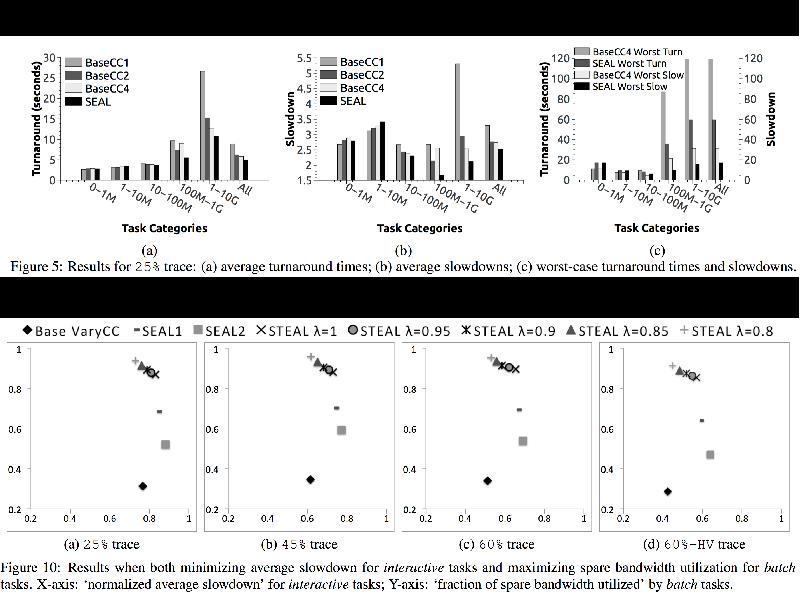
A load-aware, adaptive algorithm:
(1) Data-driven model of throughput
Слайд 19
Описание слайда:
A load-aware, adaptive algorithm:
(2) Concurrency-constrained scheduling
Define transfer priority:
Schedule transfers if neither source nor destination is saturated, using model to decide concurrency
If source or destination is saturated, interrupt active transfer(s) to service waiting requests, if in so doing can reduce overall average slowdown
Should a new transfer be scheduled?
When scheduling a transfer, with what concurrency?
When should active transfer be preempted?
When change concurrency of active transfer?
Слайд 20
Описание слайда:
Слайд 21
Описание слайда:
Слайд 22
Описание слайда:
Robust analytic models for science at extreme scales
Gagan Agarwal1* Prasanna Balaprakash2 Ian Foster2* Raj Kettimuthu2
Sven Leyffer2 Vitali Morozov2 Todd Munson2 Nagi Rao3*
Saday Sadayappan1 Brad Settlemyer3 Brian Tierney4* Don Towsley5* Venkat Vishwanath2 Yao Zhang2
1 Ohio State University 2 Argonne National Laboratory
3 Oak Ridge National Laboratory 4 ESnet 5 UMass Amherst (* Co-PIs)
Слайд 23
Описание слайда:
How to create more accurate, useful, and portable models of distributed systems?
Simple analytical model:
T= α+ β*l
[startup cost + sustained bandwidth]
Experiment + regression to estimate α, β
Слайд 24
Описание слайда:
Differential regression for combining
data from different sources
Example of use: Predict performance on connection length L not realizable on physical infrastructure
E.g., IB-RDMA or HTCP throughput on 900-mile connection
Make multiple measurements of performance on path lengths d:
Ms(d): OPNET simulation
ME(d): ANUE-emulated path
MU(di): Real network (USN)
Compute measurement regressions on d: ṀA(.), A∈{S, E, U}
Compute differential regressions: ∆ṀA,B(.) = ṀA(.) - ṀB(.), A, B∈{S, E, U}
Apply differential regression to obtain estimates, C∈{S, E}
��U(d) = MC(d) - ∆ṀC,U(d)
Слайд 25
Описание слайда:
End-to-end profile composition
Слайд 26
Описание слайда:
Three big data challenges
Channel massive flows
Automate management
Build discovery engines
Слайд 27
Описание слайда:
Слайд 28
Описание слайда:
One researcher’s perspective
on data management challenges
Слайд 29
Описание слайда:
Слайд 30
Описание слайда:
Tripit exemplifies process automation
Me
Book flights
Book hotel
Слайд 31
Описание слайда:
How the “business cloud” works
Слайд 32
Описание слайда:
Process automation for science
Слайд 33
Описание слайда:
Globus research data management services
Слайд 34
Описание слайда:
Reliable, secure, high-performance file transfer and synchronization
“Fire-and-forget” transfers
Automatic fault recovery
Seamless security integration
Powerful GUI
and APIs
Слайд 35
Описание слайда:
Simple, secure sharing off existing storage systems
Слайд 36
Описание слайда:
Extreme ease of use
InCommon, Oauth, OpenID, X.509, …
Credential management
Group definition and management
Transfer management and optimization
Reliability via transfer retries
Web interface, REST API, command line
One-click “Globus Connect Personal” install
5-minute Globus Connect Server install
Слайд 37
Описание слайда:
Слайд 38
Описание слайда:
Слайд 39
Описание слайда:
High-speed transfers to/from AWS cloud,
via Globus transfer service
UChicago AWS S3 (US region): Sustained 2 Gbps
2 GridFTP servers, GPFS file system at UChicago
Multi-part upload via 16 concurrent HTTP connections
AWS AWS (same region): Sustained 5 Gbps
Слайд 40
Описание слайда:
Globus transfer & sharing; identity & group management, data discovery & publication
Слайд 41
Описание слайда:
Globus under the covers
Слайд 42
Описание слайда:
Globus under the covers
Слайд 43
Описание слайда:
Слайд 44
Описание слайда:
Globus Platform-as-a-Service
Слайд 45
Описание слайда:
The Globus Galaxies platform:
Science as a service
Слайд 46
Описание слайда:
Three big data challenges
Channel massive flows
Automate management
Build discovery engines
Слайд 47
Описание слайда:
Discovery engines: Integrate simulation, experiment, and informatics
Слайд 48
Описание слайда:
A discovery engine for metagenomics
Слайд 49
Описание слайда:
Слайд 50
Описание слайда:
DOE Systems Biology Knowledge Base (KBase)
Слайд 51
Описание слайда:
Слайд 52
Описание слайда:
A discovery engine
for the study of disordered structures
Слайд 53
Описание слайда:
Immediate assessment of alignment quality in near-field high-energy diffraction microscopy
Слайд 54
Описание слайда:
New data, computational capabilities, and methods create opportunities and challenges
Слайд 55
Описание слайда:
Big Data to Knowledge: bd2k.org
Слайд 56
Описание слайда:
Three big data challenges
Channel massive flows
New protocols and management algorithms
Automate management
The Discovery Cloud
Build discovery engines
MG-RAST, kBase, Materials
Слайд 57
Описание слайда:
My work is supported by:
Слайд 58
Описание слайда:
Thank you!
foster@anl.gov
ianfoster.org
Скачать презентацию на тему Taming Big Data! можно ниже: