Архитектура вычислительных систем. Терминология, классификационные принципы презентация
Содержание
- 6. КЛАССИФИКАЦИЯ ВС ПОТОКАМ ПК\ПД (Flynn)
- 7. КЛАССЫ КЛАССИФИКАЦИИ ПО ПОТОКАМ SISD – фон-Неймановская архитектура: каждая команда арифметической
- 8. КЛАССИФИКАЦИЯ ВС ПОТОКАМ ПК\ПД (Flynn)
- 10. КЛАССЫ КЛАССИФИКАЦИИ ШОРА I – обычная ВМ с последовательной обработкой слов
- 12. КЛАССЫ КЛАССИФИКАЦИИ ШОРА IV – ансамбль ПРЦ получается путем интеграции модулей
- 13. КЛАССИФИКАЦИЯ ПО СТЕПЕНИ ПАРАЛЛЕЛИЗМА ОБРАБОТКИ
- 15. ЗАКОНЫ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ
- 16. ЗАКОНЫ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ Закон Джина Амдала в более точной формулировке:
- 18. КЛАССИФИКАЦИЯ СВЯЗЕЙ МЕЖДУ ЭЛЕМЕНТАМИ ММА
- 20. ЧТО ПОСЛЕ СУПЕРСКАЛЯРНОЙ АРХИТЕКТУРЫ СУПЕРСКАЛЯРНУЮ АРХИТЕКТУРУ сменит Мультимашинная (MultyСore)
- 25. Тест 1 Найти в интернете и распечатать описания архитектур современных ВС
- 26. Intel Itanium
- 27. Intel Itanium 2
- 28. Intel Itanium 2 Montecito
- 29. ARM
- 30. ARM
- 33. Core 2 Micro architecture
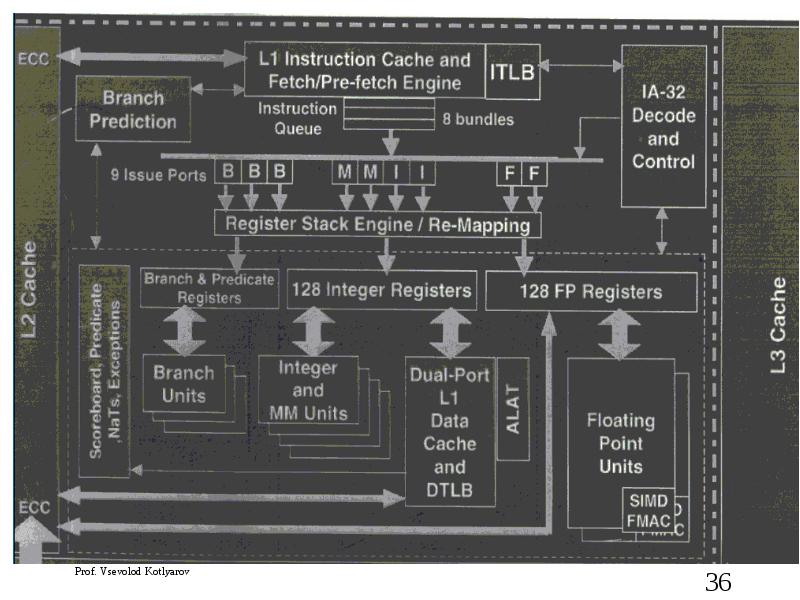
- 35. Intel Itanium VLIW Architecture
- 39. Elbrus 2K
- 40. AMD 64 Athlonex
- 42. NEC SX5
- 43. Характеристики
- 44. Скачать презентацию



")

")






")















Слайды и текст этой презентации
Слайд 1
Описание слайда:
РАЗДЕЛ 1
ТЕРМИНОЛОГИЯ
КЛАССИФИКАЦИОННЫЕ ПРИНЦИПЫ
Слайд 2
Описание слайда:
Слайд 3
Описание слайда:
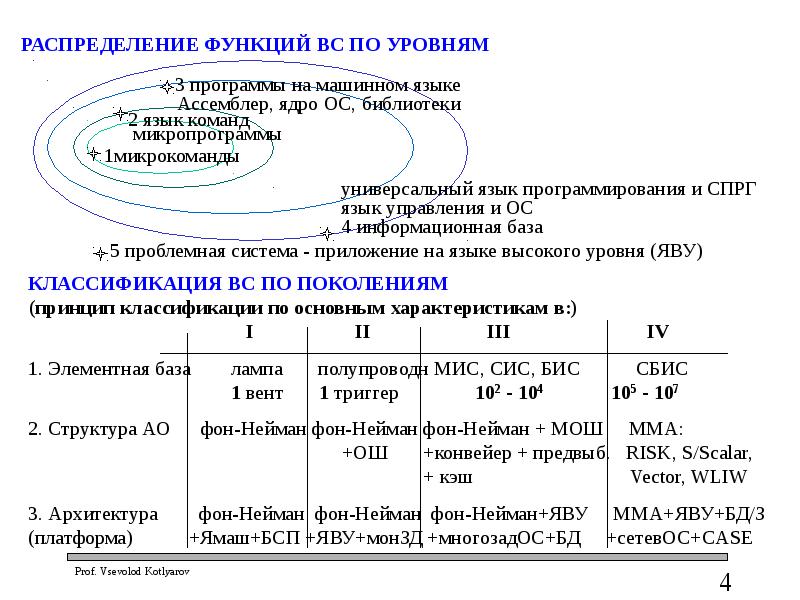
Слайд 4
Описание слайда:
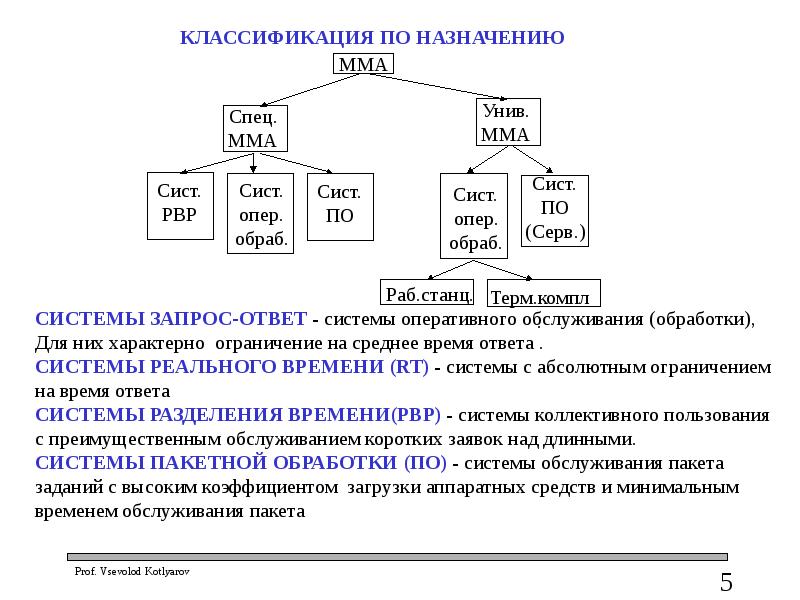
Слайд 5
Описание слайда:
Слайд 6
Описание слайда:
КЛАССИФИКАЦИЯ ВС ПОТОКАМ ПК\ПД (Flynn)
Слайд 7
Описание слайда:
КЛАССЫ КЛАССИФИКАЦИИ ПО ПОТОКАМ
SISD – фон-Неймановская архитектура: каждая команда арифметической обработки инициирует выполнение одной арифметической операции:
► Единое вычислительное устройство из ПРЦ, ОП, последовательного УУ
► Линейная структура адресации памяти (ОП – вектор слов)
► Низкий уровень машинного языка – отсутствие типов слов
SIMD – векторная архитектура:
► Векторная команда обеспечивает одновременное выполнение операций в нескольких (m) арифметических ПРЦ
► ОП должна быть либо в m раз скорее, либо расслоена (разделена) на m секций с независимым доступом
MISD – конвейерная архитектура:
► Обеспечивает одновременное выполнение множества операций одной формулы, связанных по промежуточным результатам
► Одновременное выполнение множества операций не связанных промежуточными результатами и принадлежащих либо разным формулам, либо независимо вычисляемым фрагментам одной формулы
MIMD – архитектура многопроцессорной матрицы
Слайд 8
Описание слайда:
КЛАССИФИКАЦИЯ ВС ПОТОКАМ ПК\ПД (Flynn)
Слайд 9
Описание слайда:
Слайд 10
Описание слайда:
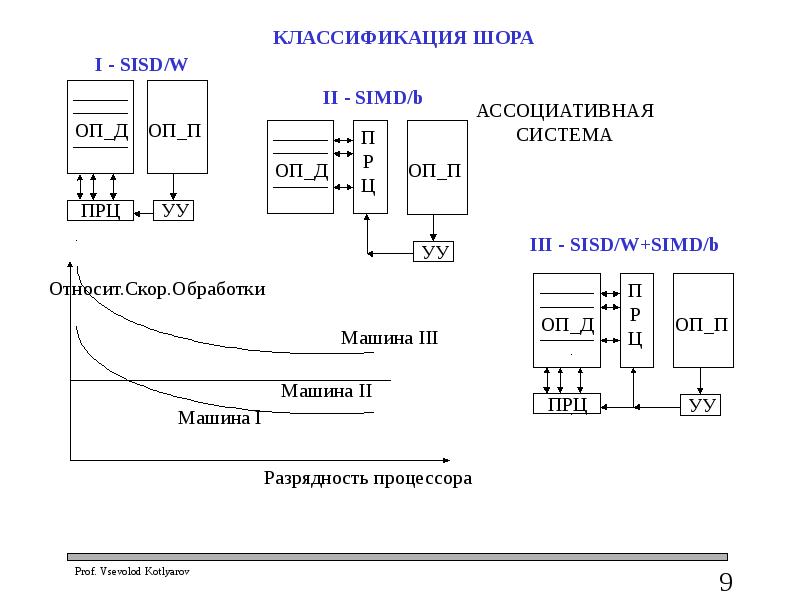
КЛАССЫ КЛАССИФИКАЦИИ ШОРА
I – обычная ВМ с последовательной обработкой слов и параллельной обработкой разрядов слов (считывание данных – параллельная выборка всех разрядов слова)
II – система с параллельной обработкой слов и последовательной обработкой разрядов в ассоциативном (вертикальном) ПРЦ за одну команду осуществляет параллельную обработку 1 разряда всех слов ОП (или разрядного среза). За счет этого поразрядно осуществляется параллельный поиск или обработка всех слов ОП одновременно. Адресация и выбор данных осуществляется по разрядам, выделенным маской и удовлетворяющим отношению из множества { = ≠ < ≤ > ≥ min max}
Достигается высокая скорость выполнения логических операций и их последовательностей, скорость выполнения арифметических операций ниже, чем в I.
III - ортогональная система объединяет преимущества машин I и II. Обеспечивается эффективный поиск данных при обработке разрядных срезов в вертикальном ПРЦ и эффективная обработка найденных слов в горизонтальном ПРЦ
Слайд 11
Описание слайда:
Слайд 12
Описание слайда:
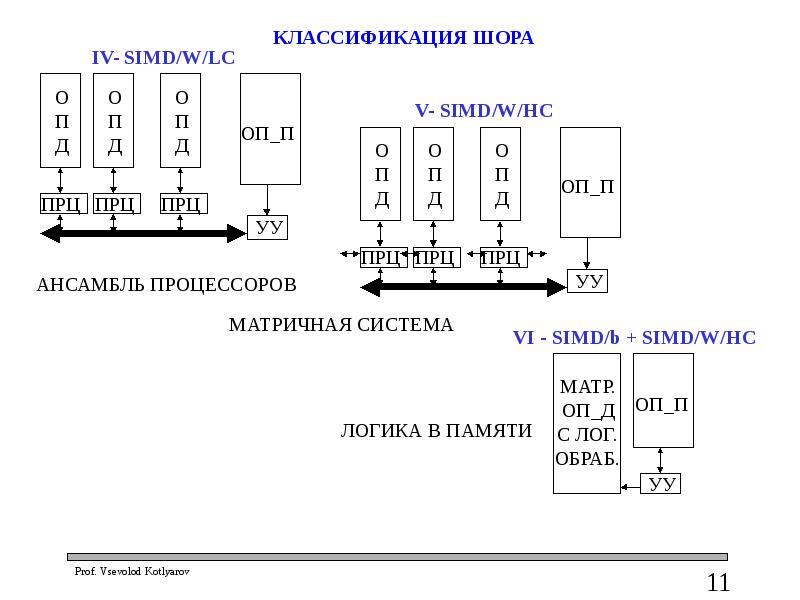
КЛАССЫ КЛАССИФИКАЦИИ ШОРА
IV – ансамбль ПРЦ получается путем интеграции модулей машины I в единую вычислительную структуру с общей шиной. Эта структура эффективна для обработки векторов, но по сравнению с машиной I скорость обработки < lg2M
V – матричная структура, получается введением наряду с ОШ прямых связей между соседними ПРЦ. Структура эффективна для обработки векторов и матриц, по сравнению с машиной I скорость обработки ~ lg2M
VI – объединяет логическую обработку с ассоциативным поиском прямо в ОП, поскольку в матричной ОП содержатся элементы логической обработки, которые осуществляют погические операции на проходе при доступе к ячейкам ОП
Слайд 13
Описание слайда:
КЛАССИФИКАЦИЯ ПО СТЕПЕНИ ПАРАЛЛЕЛИЗМА ОБРАБОТКИ
Слайд 14
Описание слайда:
Слайд 15
Описание слайда:
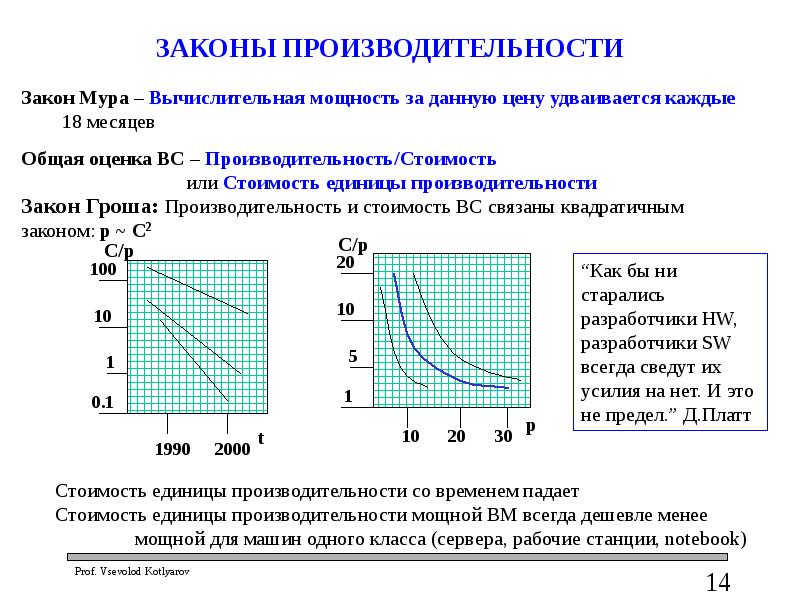
ЗАКОНЫ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ
Слайд 16
Описание слайда:
ЗАКОНЫ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ
Закон Джина Амдала в более точной формулировке:
P=N/(X*N+1-X),
где X – последовательная часть вычислений,
N – число обработчиков (процессоров),
P – степень распараллеливания.
Слайд 17
Описание слайда:
Слайд 18
Описание слайда:
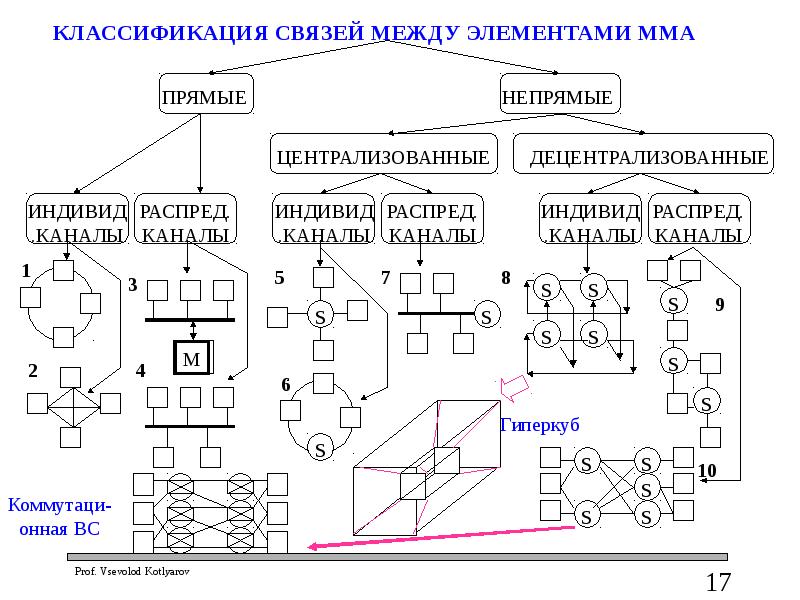
КЛАССИФИКАЦИЯ СВЯЗЕЙ МЕЖДУ ЭЛЕМЕНТАМИ ММА
Слайд 19
Описание слайда:
Слайд 20
Описание слайда:
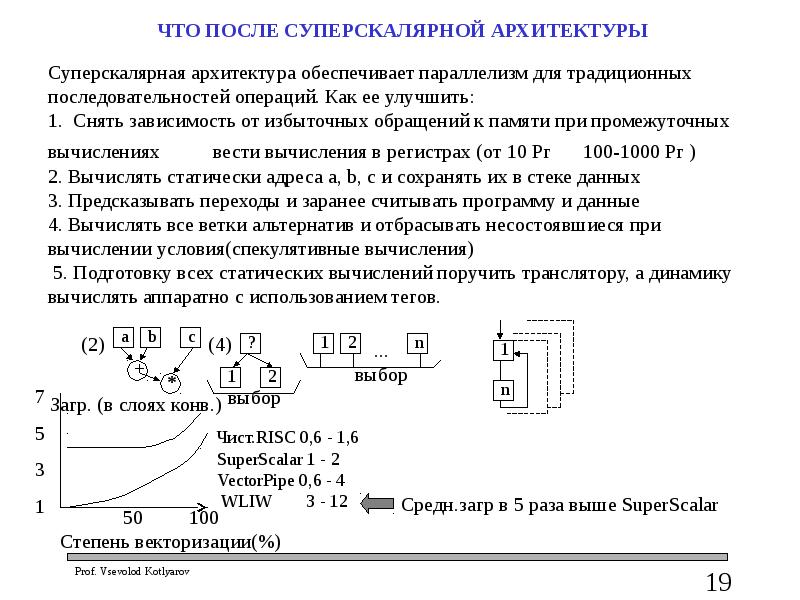
ЧТО ПОСЛЕ СУПЕРСКАЛЯРНОЙ АРХИТЕКТУРЫ
СУПЕРСКАЛЯРНУЮ АРХИТЕКТУРУ сменит Мультимашинная (MultyСore)
Слайд 21
Описание слайда:
Слайд 22
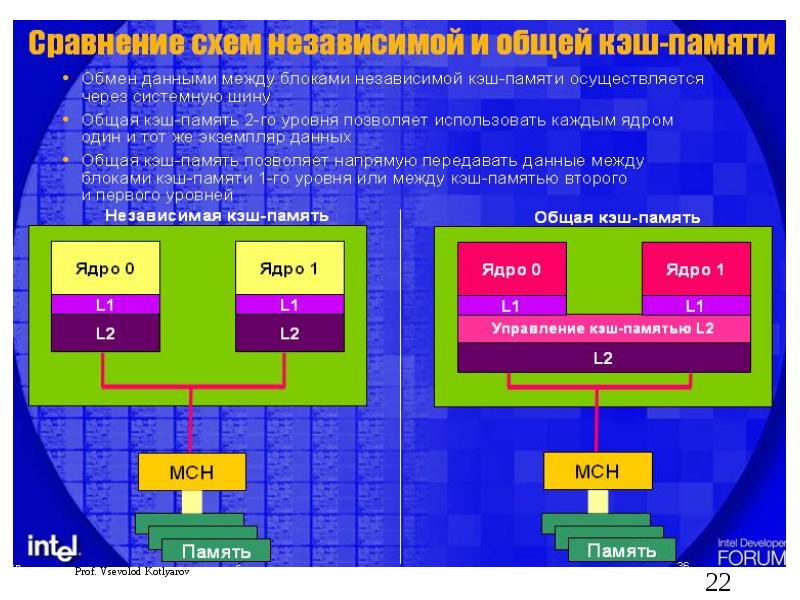
Описание слайда:
Слайд 23
Описание слайда:
Слайд 24
Описание слайда:
Слайд 25
Описание слайда:
Тест 1
Найти в интернете и распечатать описания архитектур современных ВС известных фирм:
Intel
Sun
IBM
HP
и подготовиться классифицировать архитектуры по степени параллелизма обработки и типам связей в соответствии с выданным заданием
Слайд 26
Описание слайда:
Intel
Itanium
Слайд 27
Описание слайда:
Intel
Itanium 2
Слайд 28
Описание слайда:
Intel Itanium 2 Montecito
Слайд 29
Описание слайда:
ARM
Слайд 30
Описание слайда:
ARM
Слайд 31
Описание слайда:
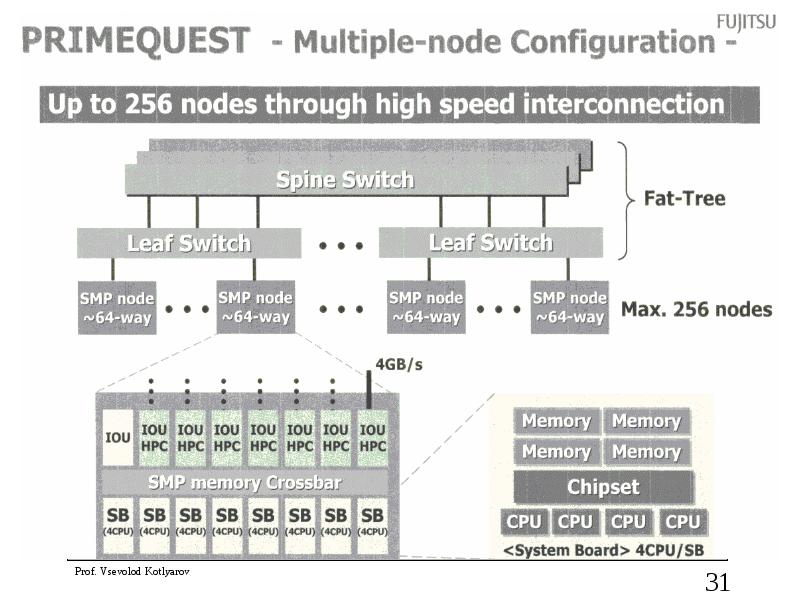
Слайд 32
Описание слайда:
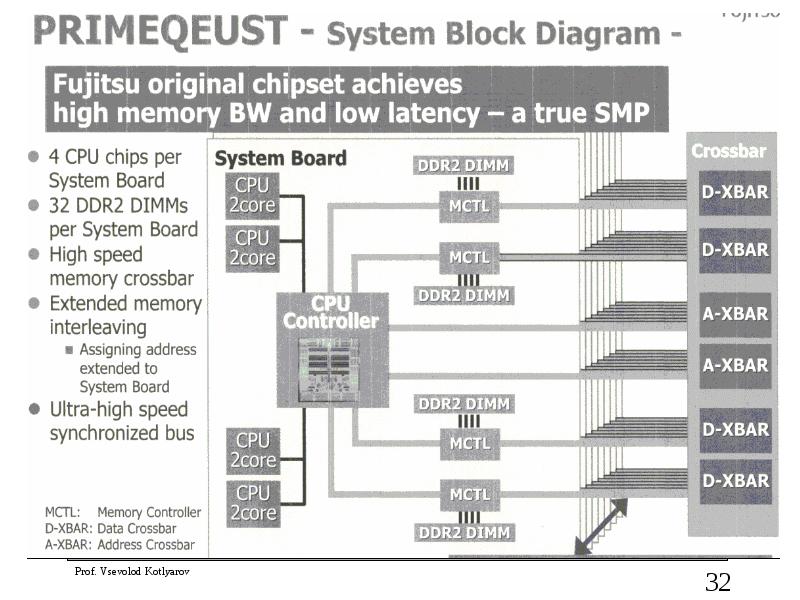
Слайд 33
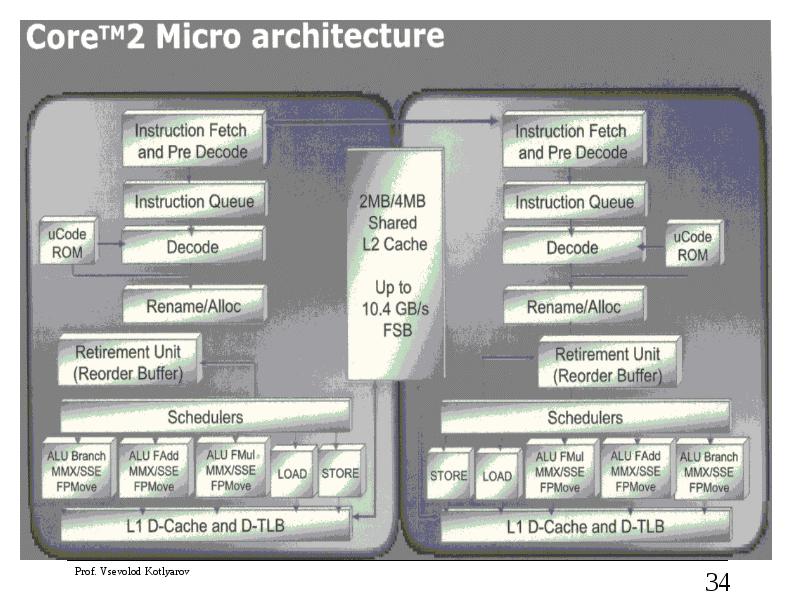
Описание слайда:
Core 2
Micro architecture
Слайд 34
Описание слайда:
Слайд 35
Описание слайда:
Intel Itanium VLIW Architecture
Слайд 36
Описание слайда:
Слайд 37
Описание слайда:
Слайд 38
Описание слайда:
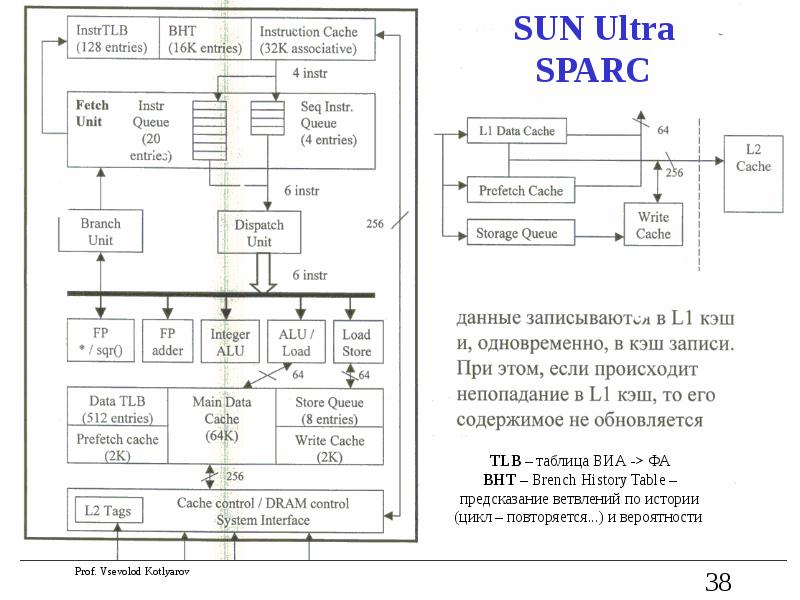
Слайд 39
Описание слайда:
Elbrus 2K
Слайд 40
Описание слайда:
AMD 64
Athlonex
Слайд 41
Описание слайда:
Слайд 42
Описание слайда:
NEC
SX5
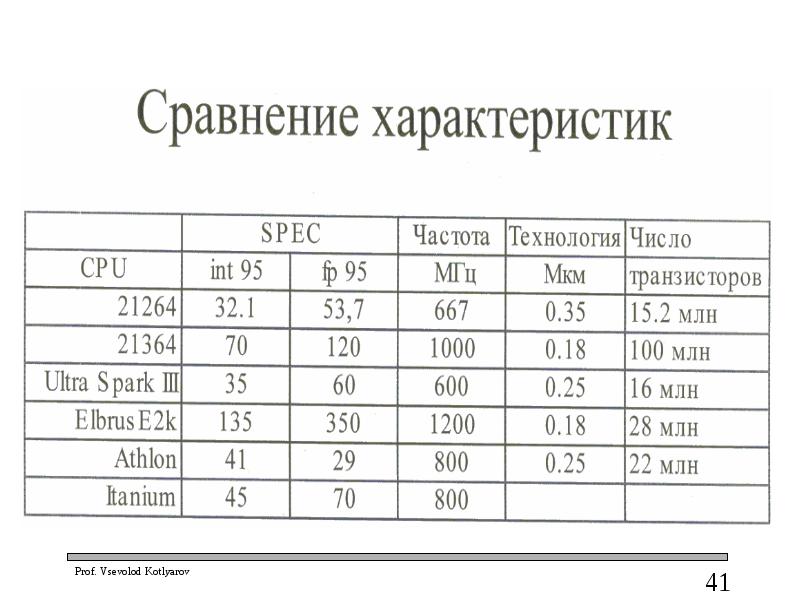
Слайд 43
Описание слайда:
Характеристики
Скачать презентацию на тему Архитектура вычислительных систем. Терминология, классификационные принципы можно ниже:





























