Молекулярные базы данных. Принцип действия и характеристики основных компьютерных программ презентация
Содержание
- 2. Новейшим методом изучения природных молекул является применение информационных систем. Новейшим
- 3. Компьютерным моделированием молекулярно-генетических и смежных процессов занимаются такие науки как биоинформатика,
- 4. Биоинформатика Биоинформатика — это область науки, разрабатывающая и применяющая вычислительные алгоритмы
- 5. Биоинформатика включает в себя: Биоинформатика включает в себя: базы данных, в
- 6. Задачи, решаемые биоинформатикой
- 7. Биолог в биоинформатике обычно имеет дело с базами данных и инструментами
- 8. Второй тип – курируемые базы данных, за достоверность которых отвечает хозяин
- 9. Поддержание базы требует работы кураторов или аннотаторов. Тем не менее, даже в
- 10. Третий тип – производные базы данных. Такие базы получаются в результате
- 11. И интегрированные базы данных, в которых вся информация (курируемая, не курируемая)
- 12. Теперь перейдем к рассмотрению инструментов биоинформатики. Инструменты определяются задачами, которые мы
- 13. Как сравнивают последовательности? Запишем одну последовательность под другой: Как сравнивают последовательности?
- 14. Таким образом, первым делом после секвенирования последовательности ищут в базах данных
- 15. Молекулярно-генетические данные хранятся в специализированных банках данных (все на английском языке):
- 16. удобная в навигации база генетических последовательностей – Ensembl удобная в
- 17. удобный доступ к полным геномам через сайт Европейского института биоинформатики -
- 18. крупнейший банк белковых данных – UniProt.org крупнейший банк белковых данных
- 19. крупнейший банк данных о структуре биологических макромолекул http://www.pdb.org/ крупнейший банк
- 20. Информационные системы, касающиеся моделей макромолекул и надмолекулярных структур: GeneBank &
- 22. CAZy: Carbohydrate-Active Enzymes Database. На сайте представлена современная классификация ферментов синтеза
- 23. http://molbiol.edu.ru/review/01_01.html
- 29. Форматы файлов, используемых в биоинформатике FASTA >roa1_drome Rea guano receptor type
- 30. GenBank GenBank
- 36. Как добавить данные в GB?
- 37. Форматы описания белков PDB PDB-XML MMDB-Cn3D
- 38. PDB – Protein Data Bank PDB – Protein Data Bank HEADER
- 39. HELIX 1 1 GLU A 5 THR A 9 5
- 40. PDB-XML PDBML: the representation of archival macromolecular structure data in XML.
- 41. Спасибо за внимание! Спасибо за внимание!
- 42. Скачать презентацию










")



:")





















Слайды и текст этой презентации
Слайд 1
Описание слайда:
Молекулярные базы данных. Принцип действия и характеристики основных компьютерных программ для сравнения биологических последовательностей
Выполнил: магистрант второго
года обучения очной формы
по направлению
06.04.01.68 Биология
программа Общая биология
группа МБИО21
Арефьева Анастасия
Александровна
Слайд 2
Описание слайда:
Новейшим методом изучения природных молекул является применение информационных систем.
Новейшим методом изучения природных молекул является применение информационных систем.
Работая с информационными моделями молекул, исследователь обычно имеет дело с базами, банками данных и инструментами их анализа. Вследствие широкого применения информационных моделей молекул появилось новое направление – биологическая информатика (биоинформатика, компьютерная биология)
Слайд 3
Описание слайда:
Компьютерным моделированием молекулярно-генетических и смежных процессов занимаются такие науки как биоинформатика, системная биология, геномика, эволюционная генетика, протеомика, транскриптомика, метаболомика и другие, еще более узкоспециализированные дисциплины, в каждой из которых работают тысячи и десятки тысяч исследователей. Такой высокий уровень дифференциации наук связан с колоссальной сложностью и огромным объемом молекулярно-генетических данных. Например, работа с последовательностью ДНК даже простейших эукариот - дрожжей S. cerevisiae – не была бы возможна без использования компьютерных методов, не говоря уже о геноме человека.
Компьютерным моделированием молекулярно-генетических и смежных процессов занимаются такие науки как биоинформатика, системная биология, геномика, эволюционная генетика, протеомика, транскриптомика, метаболомика и другие, еще более узкоспециализированные дисциплины, в каждой из которых работают тысячи и десятки тысяч исследователей. Такой высокий уровень дифференциации наук связан с колоссальной сложностью и огромным объемом молекулярно-генетических данных. Например, работа с последовательностью ДНК даже простейших эукариот - дрожжей S. cerevisiae – не была бы возможна без использования компьютерных методов, не говоря уже о геноме человека.
Слайд 4
Описание слайда:
Биоинформатика
Биоинформатика — это область науки, разрабатывающая и применяющая вычислительные алгоритмы для систематизации и анализа генетической информации с целью определения молекулярных основ биологических процессов с последующим использованием этих знаний на практике. Ее основная задача — разработка вычислительных алгоритмов для анализа и систематизации данных о структуре и функциях биологических молекул, прежде всего нуклеиновых кислот и белков. Объем генетической информации, накапливаемой в банках данных, начал увеличиваться с возрастающей скоростью после того, как были разработаны быстрые методы секвенирования (расшифровки нуклеотидных последовательностей ДНК).
Биоинформатика возникла в 1976-1978 годах, окончательно оформилась в 1980 году со специальным выпуском журнала «Nucleic Acid Research» (NAR).
Слайд 5
Описание слайда:
Биоинформатика включает в себя:
Биоинформатика включает в себя:
базы данных, в которых хранится биологическая информация
набор инструментов для анализа тех данных, которые лежат в таких базах
правильное применение компьютерных методов для правильного решения биологических задач
Слайд 6
Описание слайда:
Задачи, решаемые биоинформатикой
Слайд 7
Описание слайда:
Биолог в биоинформатике обычно имеет дело с базами данных и инструментами их анализа. Теперь разберемся, какие базы данных бывают в зависимости от того, что в них помещают.
Биолог в биоинформатике обычно имеет дело с базами данных и инструментами их анализа. Теперь разберемся, какие базы данных бывают в зависимости от того, что в них помещают.
Первый тип – архивные базы данных, это большая свалка, куда любой может поместить все, что захочет. К таким базам относятся:
GeneBank & EMBL – здесь хранятся первичные последовательности
PDB – пространственные структуры
В качестве курьеза можно привести пример: в архивной базе данных указано, что в геноме археи (архебактерии) есть ген, кодирующий белок главного комплекса гистосовместимости, что является полной чепухой, т.к. характерно для позвоночных.
Слайд 8
Описание слайда:
Второй тип – курируемые базы данных, за достоверность которых отвечает хозяин базы данных. Туда информацию никто не присылает, ее из архивных баз данных отбирают эксперты, проверяя достоверность информации – что записано в этих последовательностях, какие есть экспериментальные основания для того, чтобы считать, что эти последовательности выполняют ту или иную функцию.
Второй тип – курируемые базы данных, за достоверность которых отвечает хозяин базы данных. Туда информацию никто не присылает, ее из архивных баз данных отбирают эксперты, проверяя достоверность информации – что записано в этих последовательностях, какие есть экспериментальные основания для того, чтобы считать, что эти последовательности выполняют ту или иную функцию.
К базам данных такого типа относятся:
Swiss- Prot – наиболее качественная база данных, содержащая аминокислотные последовательности белков
KEGG – информация о метаболизме
FlyBase – информация о Drosophila
COG – информация об ортологичных генах (гомологичные гены филогенетически родственных организмов, разошедшихся в процессе видообразования)
Слайд 9
Описание слайда:
Поддержание базы требует работы кураторов или аннотаторов. Тем не менее, даже в курируемых базах данных могут встречаться курьезные надписи, например такая забавная надпись:
Поддержание базы требует работы кураторов или аннотаторов. Тем не менее, даже в курируемых базах данных могут встречаться курьезные надписи, например такая забавная надпись:
CAUTION: AN ORF CALLED DSDC WAS ORIGINALLY (REF.3) ASSIGNED TO THE WRONG DNA STRAND AND THOUGHT TO BE A D- SERINE DEAMINASE ACTIVATOR, IT WAS THEN RESEQUENCED BY REF.2 AND STILL THOUGHT TO BE "DSDC", BUT THIS TIME TO FUNCTION AS A D-SERINE PERMEASE. IT IS REF.1 THAT SHOWED THAT DSDC IS ANOTHER GENE AND THAT THIS SEQUENCE SHOULD BE CALLED DSDX. IT SHOULD ALSO BE NOTED THAT THE C-TERMINAL PART OF DSDX (FROM 338 ONWARD) WAS ALSO SEQUENCED (REF.6 AND REF.7) AND WAS THOUGHT TO BE A SEPARATE ORF (YES, DON'T WORRY, WE ALSO HAD PROBLEMS UNDERSTANDING WHAT HAPPENED!).
По крайне мере здесь кураторы базы данных честно признаются, что не знают, как это случилось.
Слайд 10
Описание слайда:
Третий тип – производные базы данных. Такие базы получаются в результате обработки данных из архивных и курируемых баз данных. Сюда входит:
Третий тип – производные базы данных. Такие базы получаются в результате обработки данных из архивных и курируемых баз данных. Сюда входит:
SCOP – База данных структурной классификации белков (описывается структура белков)
PFAM – База данных по семействам белков
GO (Gene Ontology) – Классификация генов (попытка создания набора терминов, упорядочивания терминологии, чтобы один ген не назывался по разному, и чтобы разным генам не давали одинаковые названия)
ProDom – белковые домены
AsMamDB – альтернативный сплайсинг у млекопитающих
Слайд 11
Описание слайда:
И интегрированные базы данных, в которых вся информация (курируемая, не курируемая) свалена в кучу, и введя имя гена, можно найти всю связанную с ним информацию – в каких организмах встречается, в каком месте генома локализован, какие функции выполняет и т.д.
И интегрированные базы данных, в которых вся информация (курируемая, не курируемая) свалена в кучу, и введя имя гена, можно найти всю связанную с ним информацию – в каких организмах встречается, в каком месте генома локализован, какие функции выполняет и т.д.
NCBI Entrez – доступ к информации о нуклеотидных и аминокислотных последовательностях и структурах
Ecocyc – все о E. coli – гены, белки, метаболизм и пр.
Слайд 12
Описание слайда:
Теперь перейдем к рассмотрению инструментов биоинформатики. Инструменты определяются задачами, которые мы хотим решать.
Теперь перейдем к рассмотрению инструментов биоинформатики. Инструменты определяются задачами, которые мы хотим решать.
Основу биоинформатики составляют сравнения. Если у нас есть, например, аминокислотная последовательность, о которой у нас есть экспериментальные данные, и известны ее функции, и другая, похожая на нее последовательность, мы можем предположить, что эти последовательности выполняют сходные функции. Это задача поиска сходства последовательностей
Слайд 13
Описание слайда:
Как сравнивают последовательности? Запишем одну последовательность под другой:
Как сравнивают последовательности? Запишем одну последовательность под другой:
attgtACcTCgTgG-AA----
-----AC-TCaTaGcAAccag
Нам надо при сравнении найти наилучший вариант, так выровнять эту пару последовательностей, чтобы количество совпадений было максимальным (парное выравнивание). Качество выравнивания оценивают, назначая штрафы за несовпадение букв и за наличие пробелов (когда приходится раздвигать одну последовательность для того, чтобы получить наибольшее число совпадающих позиций)
Слайд 14
Описание слайда:
Таким образом, первым делом после секвенирования последовательности ищут в базах данных похожие последовательности, чтобы после сравнения судить о том, какие функции несет эта последовательность. Если две буквы совпали, значит они находятся под давлением отбора, они функционально важны. Известно, что аминокислоты различаются по своим свойствам, поэтому если произошла аминокислотная замена, это может почти никак не повлиять на работу белка, а может сильно его изменить.
Таким образом, первым делом после секвенирования последовательности ищут в базах данных похожие последовательности, чтобы после сравнения судить о том, какие функции несет эта последовательность. Если две буквы совпали, значит они находятся под давлением отбора, они функционально важны. Известно, что аминокислоты различаются по своим свойствам, поэтому если произошла аминокислотная замена, это может почти никак не повлиять на работу белка, а может сильно его изменить.
Например, если лизин (положительно заряженная аминокислота заменится на лейцин (похожий по созвучию, но совершенно несходный по свойствам), то для пространственной структуры и функций белка это может оказаться катастрофой. А вот замена лизина на аргинин (также положительно заряженный) может не сказаться на структуре белка.
Поэтому при сравнении аминокислотных последовательностей учитывают также матрицу сопоставления аминокислотных остатков (похожих, менее похожих и совсем непохожих).
Слайд 15
Описание слайда:
Молекулярно-генетические данные хранятся в специализированных банках данных (все на английском языке):
Молекулярно-генетические данные хранятся в специализированных банках данных (все на английском языке):
крупнейшая база генетических данных – GeneBank
Слайд 16
Описание слайда:
удобная в навигации база генетических последовательностей – Ensembl
удобная в навигации база генетических последовательностей – Ensembl
Слайд 17
Описание слайда:
удобный доступ к полным геномам через сайт Европейского института биоинформатики - http://www.ebi.ac.uk/genomes/
удобный доступ к полным геномам через сайт Европейского института биоинформатики - http://www.ebi.ac.uk/genomes/
Слайд 18
Описание слайда:
крупнейший банк белковых данных – UniProt.org
крупнейший банк белковых данных – UniProt.org
Слайд 19
Описание слайда:
крупнейший банк данных о структуре биологических макромолекул http://www.pdb.org/
крупнейший банк данных о структуре биологических макромолекул http://www.pdb.org/
Слайд 20
Описание слайда:
Информационные системы, касающиеся моделей макромолекул и надмолекулярных структур:
GeneBank & EMBL – здесь хранятся первичные последовательности
PDB – пространственные структуры белков
Swiss-Prot – наиболее качественная база данных, содержащая аминокислотные последовательности белков
KEGG – информация о метаболизме (такая, которая представлена на карте метаболических путей)
SCOP – база данных структурной классификации белков (описывается структура белков)
PFAM – база данных по семействам белков
GO (Gene Ontology) – классификация генов (попытка создания набора терминов, упорядочивания терминологии)
ProDom – белковые домены
AsMamDB – альтернативный сплайсинг у млекопитающих
NCBI Entrez – доступ к информации о нуклеотидных и аминокислотных последовательностях и структурах
Ecocyc – все о E. coli – гены, белки, метаболизм и пр.
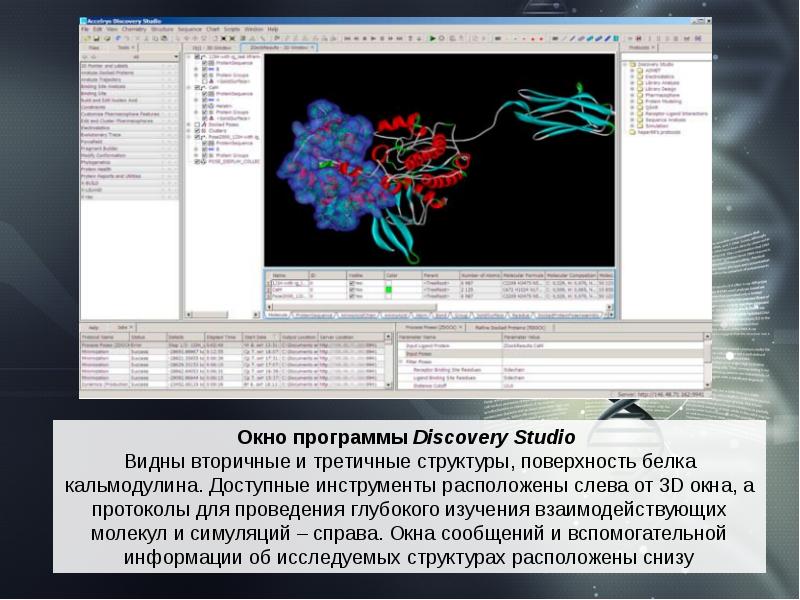
Accelrys Discovery Studio
Слайд 21
Описание слайда:
Слайд 22
Описание слайда:
CAZy: Carbohydrate-Active Enzymes Database.
На сайте представлена современная классификация ферментов синтеза и утилизации углеводов, а также их гомологов. Ферменты (а точнее каждый из их модулей/доменов) разбиты на пять групп: Glycosidases and Transglycosidases, Glycosyltransferases, Polysaccharide Lyases, Carbohydrate Esterases, Carbohydrate-Binding Modules. В пределах каждого из них выделяются семейства, которые нумеруются арабскими цифрами в порядке описания. Каждое семейство объединяет "хорошие" гомологи. Родственные семейства объединены в кланы. Например, гликозидазы и трансгликозидазы образуют 113 семейств (GH1-GH118, кроме GH21, GH40, GH41, GH60 и GH69). Из них 50 семейств объединены в 14 кланов (GH-A–GH-N). Информация о каждом из семейств включает список его представителей из разных организмов с ссылками на базы данных аминокислотных и нуклеотидных последовательностей, указание ферментативных активностей, названий белков, наличия экспериментально определённых трёхмерных структур, данные о молекулярном механизме катализируемой реакции и компонентах активного центра. База данных обновляется примерно раз в месяц.
CAZy: Carbohydrate-Active Enzymes Database.
На сайте представлена современная классификация ферментов синтеза и утилизации углеводов, а также их гомологов. Ферменты (а точнее каждый из их модулей/доменов) разбиты на пять групп: Glycosidases and Transglycosidases, Glycosyltransferases, Polysaccharide Lyases, Carbohydrate Esterases, Carbohydrate-Binding Modules. В пределах каждого из них выделяются семейства, которые нумеруются арабскими цифрами в порядке описания. Каждое семейство объединяет "хорошие" гомологи. Родственные семейства объединены в кланы. Например, гликозидазы и трансгликозидазы образуют 113 семейств (GH1-GH118, кроме GH21, GH40, GH41, GH60 и GH69). Из них 50 семейств объединены в 14 кланов (GH-A–GH-N). Информация о каждом из семейств включает список его представителей из разных организмов с ссылками на базы данных аминокислотных и нуклеотидных последовательностей, указание ферментативных активностей, названий белков, наличия экспериментально определённых трёхмерных структур, данные о молекулярном механизме катализируемой реакции и компонентах активного центра. База данных обновляется примерно раз в месяц.
Слайд 23
Описание слайда:
http://molbiol.edu.ru/review/01_01.html
Слайд 24
Описание слайда:
Слайд 25
Описание слайда:
Слайд 26
Описание слайда:
Слайд 27
Описание слайда:
Слайд 28
Описание слайда:
Слайд 29
Описание слайда:
Форматы файлов, используемых в биоинформатике
FASTA
>roa1_drome Rea guano receptor type III >> 0.1
MVNSNQNQNGNSNGHDDDFPQDSITEPEHMRKLFIGGLDYRTTDENLKAHEKWGNIVDVVVMKDPRTKRSRGFGFITYSHSSMIDEAQKSRPHKIDGRVEPKRAVPRQDIDSPNAGATVKKLFVGALKDDHDEQSIRDYFQHFGNIVDNIVIDKETGKKRGFAFVEFDDYDPVDKVVLQKQHQLNGKMVDVKKALPKNDQQGGGGGRGGPGGRAGGNRGNMGGGNYGNQNGGGNWNNGGNNWGNNRGNDNWGNNSFGGGGGGGGGYGGGNNSWGNNNPWDNGNGGGNFGGGGNNWNGGNDFGGYQQNYGGGPQRGGGNFNNNRMQPYQGGGGFKAGGGNQGNYGNNQGFNNGGNNRRY
>roa2_drome Rea guano ligand
MVNSNQNQNGNSNGHDDDFPQDSITEPEHMRKLFIGGLDYRTTDENLKAHEKWGNIVDVVVMKDPTSTSTSTSTSTSTSTSTMIDEAQKSRPHKIDGRVEPKRAVPRQDIDSPNAGATVKKLFVGALKDDHDEQSIRDYFQHLLLLLLLDLLLLDLLLLDLLLFVEFDDYDPVDKVVLQK
QHQLNGKMVDVKKALPKNDQQGGGGGRGGPGGRAGGNRGNMGGGNYGNQNGGGNWNNGGNNWGNNRGNDNWGNNSFGGGGGGGGGYGGGNNSWGNNNPWDNGNGGGNFGGGGNNWNGGNDFGGYQQNYGGGPQRGGGNFNNNRMQPYQGGGGFKAGGGNQGNYGNNQGFNNGGNNRRY
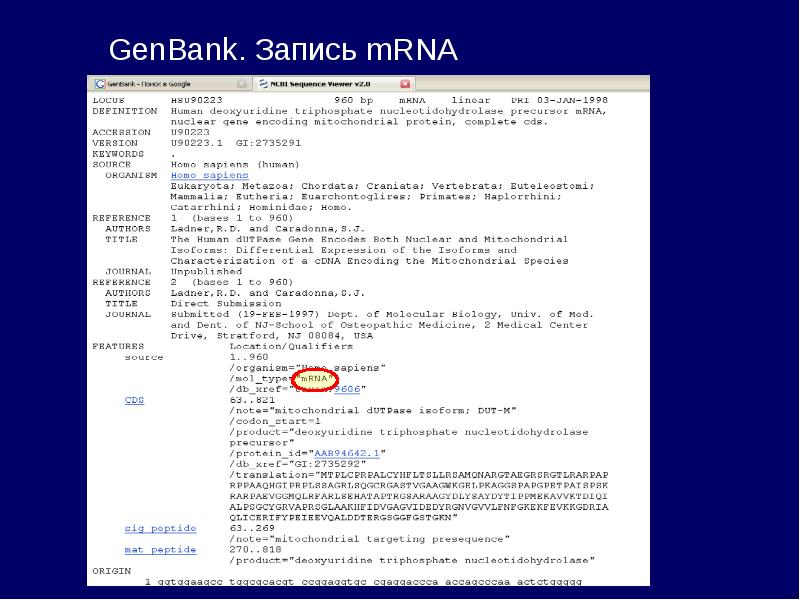
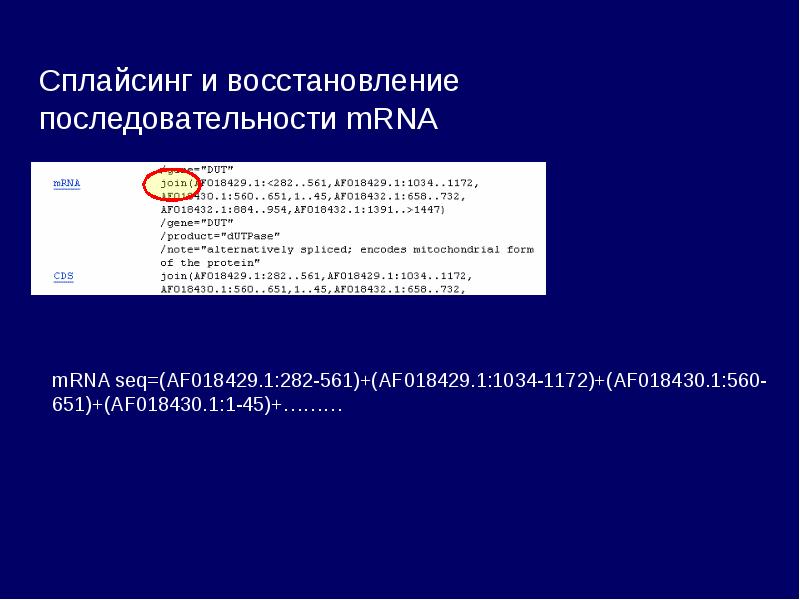
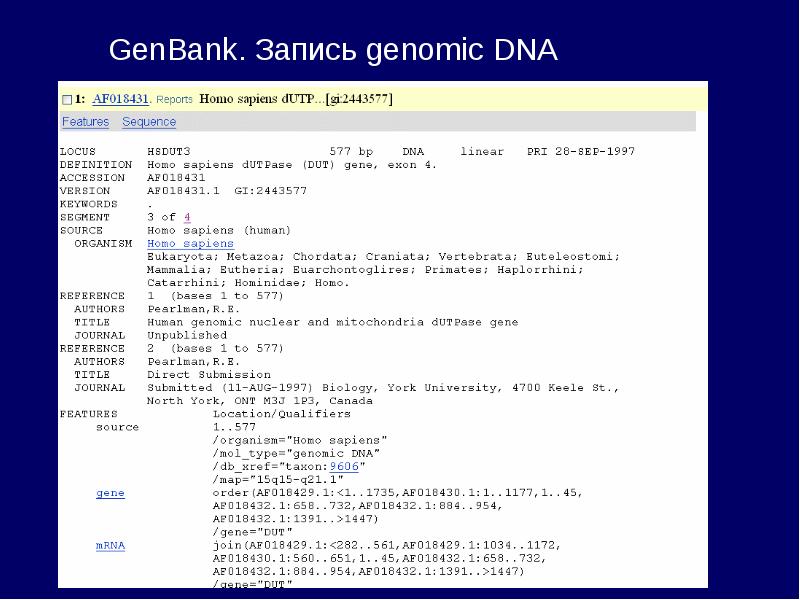
Слайд 30
Описание слайда:
GenBank
GenBank
Слайд 31
Описание слайда:
Слайд 32
Описание слайда:
Слайд 33
Описание слайда:
Слайд 34
Описание слайда:
Слайд 35
Описание слайда:
Слайд 36
Описание слайда:
Как добавить данные в GB?
Слайд 37
Описание слайда:
Форматы описания белков
PDB
PDB-XML
MMDB-Cn3D
Слайд 38
Описание слайда:
PDB – Protein Data Bank
PDB – Protein Data Bank
HEADER LUMINESCENT PROTEIN 09-DEC-03 1RRX
TITLE CRYSTALLOGRAPHIC EVIDENCE FOR ISOMERIC CHROMOPHORES IN 3-
TITLE 2 FLUOROTYROSYL-GREEN FLUORESCENT PROTEIN
COMPND MOL_ID: 1;
COMPND 2 MOLECULE: SIGF1-GFP FUSION PROTEIN;
COMPND 3 CHAIN: A;
COMPND 4 ENGINEERED: YES;
COMPND 5 OTHER_DETAILS: CONTAINS 3-FLUORO-TYROSINE
SOURCE MOL_ID: 1;
SOURCE 2 ORGANISM_SCIENTIFIC: AEQUOREA VICTORIA;
SOURCE 3 ORGANISM_COMMON: FUNGI;
SOURCE 4 EXPRESSION_SYSTEM: ESCHERICHIA COLI;
SOURCE 5 EXPRESSION_SYSTEM_COMMON: BACTERIA;
SOURCE 6 EXPRESSION_SYSTEM_VECTOR_TYPE: PLASMID
KEYWDS BETA-BARREL, EGFP, NON-CANONICAL AMINO ACID, CHROMOPHORE
KEYWDS 2 ISOMERISATION
EXPDTA X-RAY DIFFRACTION
AUTHOR J.H.BAE,P.PARAMITA PAL,L.MORODER,R.HUBER,N.BUDISA
REVDAT 1 08-JUN-04 1RRX 0
JRNL AUTH J.H.BAE,P.PARAMITA PAL,L.MORODER,R.HUBER,N.BUDISA
JRNL TITL CRYSTALLOGRAPHIC EVIDENCE FOR ISOMERIC
JRNL TITL 2 CHROMOPHORES IN 3-FLUOROTYROSYL-GREEN FLUORESCENT
JRNL TITL 3 PROTEIN.
JRNL REF CHEMBIOCHEM V. 5 720 2004
JRNL REF 2 EUROP.J.CHEM.BIOL.
JRNL REFN GE ISSN 1439-4227
REMARK 1
REMARK 2
REMARK 2 RESOLUTION. 2.10 ANGSTROMS.
REMARK 3
REMARK 3 REFINEMENT.
--------------------------------------------//-----------------------------------------------------------
REMARK 500 M RES CSSEQI ATM1 ATM2 ATM3
REMARK 500 LEU A 44 CA - CB - CG ANGL. DEV. = 13.7 DEGREES
REMARK 500 LEU A 64 N - CA - C ANGL. DEV. =-16.6 DEGREES
REMARK 500 LEU A 64 CA - C - O ANGL. DEV. =-16.0 DEGREES
REMARK 500 LEU A 64 CA - C - N ANGL. DEV. = 31.6 DEGREES
REMARK 500 LEU A 64 O - C - N ANGL. DEV. =-15.9 DEGREES
REMARK 500 THR A 97 N - CA - C ANGL. DEV. =-14.0 DEGREES
REMARK 500 GLU A 115 N - CA - C ANGL. DEV. =-13.1 DEGREES
REMARK 900
REMARK 900 RELATED ENTRIES
REMARK 900 RELATED ID: 1EMG RELATED DB: PDB
REMARK 900 THE WILD TYPE OF STUDIED NON-CANONICAL AMINO ACID-
REMARK 900 CONTAINING GFP
Слайд 39
Описание слайда:
HELIX 1 1 GLU A 5 THR A 9 5 5
HELIX 2 2 ALA A 37 YOF A 39 5 3
HELIX 3 3 PRO A 56 VAL A 61 5 6
HELIX 4 4 VAL A 68 SER A 72 5 5
HELIX 5 5 PRO A 75 HIS A 81 5 7
HELIX 6 6 ASP A 82 ALA A 87 1 6
SHEET 1 A12 VAL A 12 VAL A 22 0
SHEET 2 A12 HIS A 25 ASP A 36 -1 O GLY A 31 N VAL A 16
SHEET 3 A12 LYS A 41 CYS A 48 -1 O THR A 43 N GLU A 34
SHEET 4 A12 HIS A 217 ALA A 227 -1 O LEU A 220 N LEU A 44
SHEET 5 A12 HIS A 199 SER A 208 -1 N SER A 202 O THR A 225
SHEET 6 A12 ASN A 149 ASP A 155 -1 N ILE A 152 O HIS A 199
SHEET 7 A12 GLY A 160 ASN A 170 -1 O GLY A 160 N ASP A 155
SHEET 8 A12 VAL A 176 PRO A 187 -1 O GLN A 177 N HIS A 169
SHEET 9 A12 YOF A 92 PHE A 100 -1 N GLU A 95 O GLN A 184
SHEET 10 A12 ASN A 105 GLU A 115 -1 O YOF A 106 N ILE A 98
SHEET 11 A12 THR A 118 ILE A 128 -1 O LYS A 126 N LYS A 107
SHEET 12 A12 VAL A 12 VAL A 22 1 N ASP A 21 O GLY A 127
CISPEP 1 MET A 88 PRO A 89 0 0.50
CRYST1 51.003 62.430 70.931 90.00 90.00 90.00 P 21 21 21 4
ORIGX1 1.000000 0.000000 0.000000 0.00000
ORIGX2 0.000000 1.000000 0.000000 0.00000
ORIGX3 0.000000 0.000000 1.000000 0.00000
SCALE1 0.019607 0.000000 0.000000 0.00000
SCALE2 0.000000 0.016018 0.000000 0.00000
SCALE3 0.000000 0.000000 0.014098 0.00000
ATOM 1 N SER A 2 28.277 8.150 50.951 1.00 57.00 N
ATOM 2 CA SER A 2 27.454 9.223 51.584 1.00 55.40 C
ATOM 3 C SER A 2 25.972 8.992 51.295 1.00 55.44 C
ATOM 4 O SER A 2 25.576 7.932 50.799 1.00 54.37 O
ATOM 5 CB SER A 2 27.883 10.601 51.046 1.00 70.82 C
ATOM 6 OG SER A 2 27.150 11.676 51.622 1.00 71.45 O
ATOM 7 N LYS A 3 25.157 9.993 51.619 1.00141.28 N
ATOM 8 CA LYS A 3 23.716 9.932 51.398 1.00140.16 C
-----------------------------------//----------------------------------------------------------------
ATOM 47 CA PHE A 8 26.551 11.090 41.294 1.00 19.27 C
ATOM 48 C PHE A 8 27.751 10.357 40.676 1.00 21.43 C
ATOM 49 O PHE A 8 28.562 10.924 39.938 1.00 21.44 O
ATOM 50 CB PHE A 8 27.022 12.362 41.991 1.00 21.68 C
ATOM 51 CG PHE A 8 25.909 13.297 42.288 1.00 17.60 C
ATOM 52 CD1 PHE A 8 25.488 14.212 41.321 1.00 14.95 C
ATOM 495 CA VAL A 68 23.860 22.610 40.452 1.00 14.12 C
ATOM 496 C VAL A 68 25.259 22.196 40.854 1.00 13.41 C
ATOM 1164 CA SER A 147 37.123 31.083 35.325 1.00 21.88 C
ATOM 1819 CD1 ILE A 229 38.888 21.450 53.055 1.00 29.11 C
ATOM 1820 OXT ILE A 229 43.220 19.637 50.148 1.00 25.25 O
TER 1821 ILE A 229
Слайд 40
Описание слайда:
PDB-XML
PDBML: the representation of archival macromolecular structure data in XML. John Wesbrook, Nobutoshi Ito, Haruki Nakamura, Kim Henrick and Helen M. Berman, Bioinformatics, 21(7), 988-992, 2005.
Слайд 41
Описание слайда:
Спасибо за внимание!
Спасибо за внимание!
Скачать презентацию на тему Молекулярные базы данных. Принцип действия и характеристики основных компьютерных программ можно ниже: